목차
- 병합정렬
- 하향식 병합 정렬 (top-down)
- 상향식 병합 정렬 (bottom-up)
- 병합 정렬은 점근적으로 볼 때 최적의 비교 기반 정렬 알고리즘이다
병합정렬

병합 (merge)은 정렬 대상을 2개의 배열로 쪼갠 다음, 각각 정렬시킨 다음 큰 정렬된 배열로 다시 합치는 것을 말한다. 이때 배열을 쪼개어 정렬한 뒤 합치는 작업을 재귀적으로 수행한다면, 최종적으로 배열이 정렬된다는 것이다. 크기가 N인 배열을 정렬하는데 NlogN이 소요된다.
재귀적으로 구현한다는 것은 분할정복 패러다임 (문제를 잘게 쪼개어 각 부분을 해결한뒤 다시 전체 문제를 해결)을 사용한다는 것이다. 아래에서 살펴보겠지만, 분할정복은 다시 하향식 (top-down)으로 구현하는 방법과, 상향식 (bottom-up)으로 구현방법이 나뉜다.
단점 : 배열의 크기만큼의 추가 메모리 공간이 필요
병합 정렬의 가장 큰 단점으로는 크기 N 만큼의 추가 메모리 공간이 필요하다는 것이다. 병합 결과를 담기 위해 매 재귀마다 새로운 배열을 선언해야 한다.
즉석 병합정렬 (in-place)
- 병합 결과를 담을 새로운 배열 선언
- 분할된 두 병렬을 하나의 배열로 병합 (병합 시 양쪽 배열의 첫 번째 원소를 비교해 가며 작은 원소를 우선 추가)
- 1~2를 재귀적으로 수행
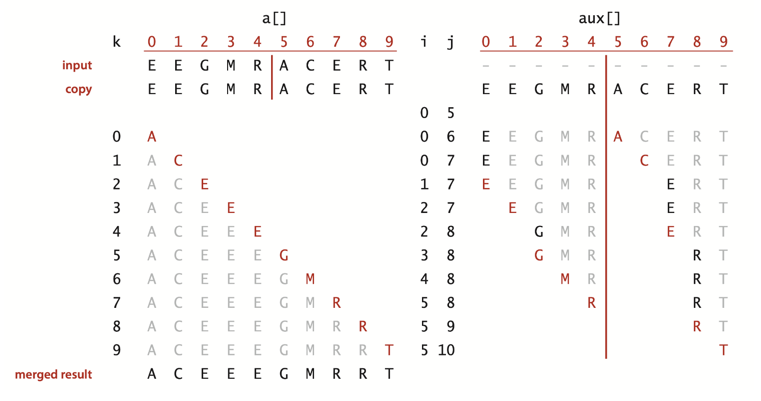
// a 배열의 정렬된 a[lo..mid]와 정렬된 a[mid+1..hi]를 병합
private static void merge(Comparable[] a, int lo, int mid, int hi) {
int i = lo, j = mid + 1;
for (int k = lo; k <= hi; k++) {
// a[lo..hi]를 aux[lo..hi]에 복사
aux[k] = a[k];
}
for (int k = lo; k <= hi; k++) {
// 병합된 결과를 a[lo..hi]에 저장
if (i > mid) a[k] = aux[j++]; // 왼쪽 절반 소진
else if (j > hi) a[k] = aux[i++]; // 오른쪽 절반 소진
else if (less(aux[j], aux[i])) a[k] = aux[j++]; // 오른쪽이 더 작으면 오른쪽 원소 삽입
else a[k] = aux[i++]; // 왼쪽이 더 작으면 왼쪽 원소 삽입
}
}
a []를 aux []에 최초 1번 복사해 두고, 원본배열 a에 병합 결과를 저장해 가는 방식으로 메모리 문제를 해결했다. 그러나 원본 배열만큼의 추가 메모리가 최소한 필요하다는 것은 여전히 문제다.
하향식 병합 정렬 (top-down)
public class Merge {
private static Comparable[] aux; // 병합을 위한 작업용 임시 배열
public static void sort(Comparable[] a) {
aux = new Comparable[a.length]; // 임시 배열 생성
sort(a, 0, a.length - 1); // 재귀 호출
}
private static void sort(Comparable[] a, int lo, int hi) {
if (hi <= lo) return; // 종료 조건
int mid = lo + (hi - lo) / 2; // 중간 지점 계산
sort(a, lo, mid); // 왼쪽 절반 정렬
sort(a, mid + 1, hi); // 오른쪽 절반 정렬
merge(a, lo, mid, hi); // 병합
}
private static void merge(Comparable[] a, int lo, int mid, int hi) {
int i = lo, j = mid + 1;
for (int k = lo; k <= hi; k++) {
// a[lo..hi]를 aux[lo..hi]에 복사
aux[k] = a[k];
}
for (int k = lo; k <= hi; k++) {
// 병합된 결과를 a[lo..hi]에 저장
if (i > mid) a[k] = aux[j++]; // 왼쪽 절반 소진
else if (j > hi) a[k] = aux[i++]; // 오른쪽 절반 소진
else if (less(aux[j], aux[i])) a[k] = aux[j++]; // 오른쪽이 더 작으면 오른쪽 원소 삽입
else a[k] = aux[i++]; // 왼쪽이 더 작으면 왼쪽 원소 삽입
}
}
public static void main(String[] args) {
String[] a = new String[]{"M", "E", "R", "G", "E", "S", "O", "R", "T", "E", "X", "A", "M", "P", "L", "E"};
sort(a);
assert Example.isSorted(a);
Example.show(a);
}
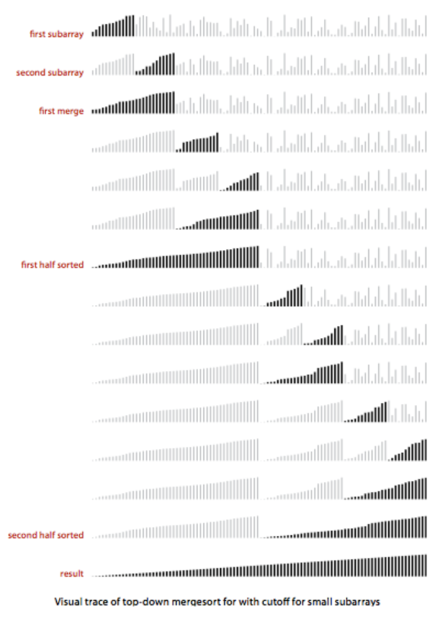
}sort(a, 0, 15)
sort(a, 0, 7)
sort(a, 0, 3)
sort(a, 0, 1)
merge(a, 0, 0, 1)
sort(a, 2, 3)
merge(a, 2, 2, 3)
sort(a, 4, 7)
sort(a, 4, 5)
merge(a, 4, 4, 5)
sort(a, 6, 7)
merge(a, 6, 6, 7)
merge(a, 0, 3, 7)
sort(a, 8, 15)
sort(a, 8, 11)
sort(a, 8, 9)
merge(a, 8, 8, 9)
sort(a, 10, 11)
merge(a, 10, 10, 11)
sort(a, 12, 15)
sort(a, 12, 13)
merge(a, 12, 12, 13)
sort(a, 14, 15)
merge(a, 14, 14, 15)
merge(a, 8, 11, 15)
merge(a, 0, 7, 15)
부분 배열 a [lo.. hi]를 정렬하기 위해 sort(a, lo, hi)를 호출하면,
- a [lo.. mid]와 a [mid+1.. hi]로 분할
- 각 부분 배열에 대해 정렬
- 부분 배열을 병합
- 1~3을 재귀적으로 수행
매우 큰 배열에 대해서도 logN에 비례하는 실행성능을 가진다. 그렇기 때문에 매우 큰 배열에 대해서도 적용이 가능하다. 그러나 매 merge 마다 임시 배열을 위한 추가 메모리 공간 (aux [])가 필요하다는 단점이 있다. 메모리 절약이 매우 중요하다면, 다른 정렬 알고리즘을 고민해봐야 한다.
성능 개선 1. 작은 부분배열은 삽입 정렬 사용하기
재귀적으로 정렬을 수행할 때, 부분배열의 크기가 충분히 작다면 삽입 정렬로 정렬하는 방법이 있다. 작은 배열은 삽입 정렬 (혹은 선택정렬)이 동작이 더단순하여 빠르기 때문이다. 작은 부분배열은 보통 크기 15 이하로 잡는다. (15 이하일 때 10 ~ 15% 빠르다고 알려져 있음)
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class CompareSortingMerge {
private Double[] generateRandomArray(int i) {
Double[] arr = new Double[i];
for (int j = 0; j < i; j++) {
arr[j] = Math.random();
}
return arr;
}
@Benchmark
public void sorting_insertion() {
Double[] arr = generateRandomArray(15);
Insertion.sort(arr);
}
@Benchmark
public void sorting_merge() {
Double[] arr = generateRandomArray(15);
Merge.sort(arr);
}
@Benchmark
public void sorting_insertion_big() {
Double[] arr = generateRandomArray(1000);
Insertion.sort(arr);
}
@Benchmark
public void sorting_merge_big() {
Double[] arr = generateRandomArray(1000);
Merge.sort(arr);
}
}Benchmark Mode Cnt Score Error Units
CompareSortingMerge.sorting_insertion_big avgt 5 514.804 ± 346.030 us/op
CompareSortingMerge.sorting_merge_big avgt 5 107.246 ± 1.642 us/op
CompareSortingMerge.sorting_merge avgt 5 0.733 ± 0.010 us/op
CompareSortingMerge.sorting_insertion avgt 5 0.416 ± 0.009 us/op
내 PC에서는 (M1 Max, 32GB) 크기가 15인 배열은 경우 삽입 정렬이 약 45% 빠르게 측정되었다.
성능 개선 2. 배열이 이미 정렬된 상태라면 정렬 작업 skip
부분배열 양쪽의 크기가 완전히 정렬되어 있다면, 병합 과정을 생략하고 바로 원본 배열을 반환하는 방법이다. a [mid] <= a [mid+1]이라면, 양 부분배열은 병합 시 정렬 작업이 필요 없으므로, merge()를 호출하지 않고 바로 반환하게 한다.
상향식 병합 정렬 (bottom-up)

public class MergeBU {
private static Comparable[] aux; // 병합을 위한 작업용 임시 배열
public static void sort(Comparable[] a) {
int N = a.length;
aux = new Comparable[N]; // 임시 배열 생성
for (int sz = 1; sz < N; sz = sz + sz) // sz: 부분 배열의 크기
for (int lo = 0; lo < N - sz; lo += sz + sz) // lo: 부분 배열의 인덱스
merge(a, lo, lo + sz - 1, Math.min(lo + sz + sz - 1, N - 1)); // 병합
}
private static void merge(Comparable[] a, int lo, int mid, int hi) {
int i = lo, j = mid + 1;
for (int k = lo; k <= hi; k++) {
// a[lo..hi]를 aux[lo..hi]에 복사
aux[k] = a[k];
}
for (int k = lo; k <= hi; k++) {
// 병합된 결과를 a[lo..hi]에 저장
if (i > mid) a[k] = aux[j++]; // 왼쪽 절반 소진
else if (j > hi) a[k] = aux[i++]; // 오른쪽 절반 소진
else if (less(aux[j], aux[i])) a[k] = aux[j++]; // 오른쪽이 더 작으면 오른쪽 원소 삽입
else a[k] = aux[i++]; // 왼쪽이 더 작으면 왼쪽 원소 삽입
}
}
public static void main(String[] args) {
String[] a = new String[]{"M", "E", "R", "G", "E", "S", "O", "R", "T", "E", "X", "A", "M", "P", "L", "E"};
sor(a);
assert Example.isSorted(a);
Example.show(a);
}
}// sz = 1
merge(a, 0, 0, 1)
merge(a, 2, 2, 3)
merge(a, 4, 4, 5)
merge(a, 6, 6, 7)
merge(a, 8, 8, 9)
merge(a, 10, 10, 11)
merge(a, 12, 12, 13)
merge(a, 14, 14, 15)
// sz = 2
merge(a, 0, 1, 3)
merge(a, 4, 5, 7)
merge(a, 8, 9, 11)
merge(a, 12, 13, 15)
// sz = 4
merge(a, 0, 3, 7)
merge(a, 8, 11, 15)
// sz = 8
merge(a, 0, 7, 15)
하향식 방법은 재귀를 통해 분할정복을 이룬다. 즉 큰 문제를 작은 문제로 나누는 것을 재귀로 구현한다. 상향식은 재귀 호출을 사용하지 않는다. 작은 문제를 먼저 정의하고 해결된 작은 문제를 병합해 조금 더 큰 문제를 해결해 나가는 식이다.
병합 정렬은 점근적으로 볼 때 최적의 비교 기반 정렬 알고리즘이다
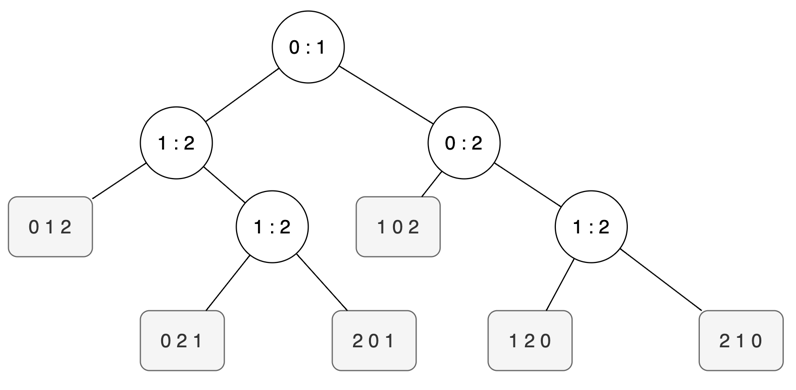
위 트리에서 노드에서 왼쪽으로 가는 경우는 노드의 비교 결과 왼쪽 값이 더 작을 때이다. 예를 들어 루트노드에서 왼쪽으로 갔다는 것은 키 0이 키 1보다 작을 때를 말한다. 위 트리 모델을 토대로 몇 가지를 정리해 볼 수 있는데,
- 이진트리에서 트리의 높이가 h라면, 잎 노드는 최대 2^h개
- 최소한 N! 개의 리프 노드가 필요 (N개의 서로 다른 키가 정렬되는 경우의 수는 순열 N개)
- 루트에서 리프노드까지의 겨리 = 비교 연산 횟수
- 트리의 높이 = 최악의 비교 횟수
- N! <= 리프 노드 개수 <= 2^h
위 정리를 토대로 최악의 경우 h (비교 연산 횟수)는 log(N!) <= h이다. 즉 최악의 조건에서 병합 정렬은 NlogN 번에 비례하도록 비교 연산을 수행한다. 따라서 정렬 알고리즘의 성능을 비교 연산 횟수에 둔다면, 병합 정렬은 최적의 비교 기반 정렬 알고리즘이다.
병합 정렬의 한계
- 공간(메모리) 활용에 있어 최적이라 볼 수 없다. (병합마다 새로운 임시 배열 필요)
- 비교 연산보다 성능에 더 중요한 연산이 있을 수 있다. (e.g. 배열 접근 비용이 비교 비용보다 훨씬 큰 경우)
- 비교 연산을 사용하지 않고도 정렬이 가능한 데이터가 존재할 수 있다.
참고
https://product.kyobobook.co.kr/detail/S000001792777
알고리즘 | 로버트 세지윅 - 교보문고
알고리즘 | 알고리즘과 자료 구조의 핵심을 담은 고전 클래식 레퍼런스 로버트 세지윅 베스트셀러의 최신 버전. 지난 수십년 동안 발전한 알고리즘과 자료 구조에 대한 내용을 한 권에 담았다.
product.kyobobook.co.kr
'Engineering > Algorithm' 카테고리의 다른 글
| [algorithm] 정렬 4. 정리 및 응용 (2) | 2024.06.22 |
|---|---|
| [algorithm] 정렬 3. 우선순위 큐 (Priority Queues) (2) | 2024.04.19 |
| [algorithm] 정렬 2. 퀵 정렬 (2) | 2024.02.04 |
| [algorithm] 기초적인 정렬 : 선택 정렬, 삽입 정렬 (1) | 2023.12.28 |




댓글