
목표
- 알고리즘의 기본을 이해한다.
- 알고리즘을 공부하기 위해 기본적인 자료구조 지식을 갖춘다.
목차
- 알고리즘이 갖는 의미
- 자료구조의 기본
알고리즘이 갖는 의미
컴퓨터 프로그램의 근본 목적은 문제 (요구사항)를 알고리즘을 이용하여 풀어내는 것입니다. 그 문제는 단순 입/출력일 수도 있고, 보다 복잡한 계산일 수도 있습니다. 프로그램이 목적에 맞게 실행할 수 있도록 제시하는 해결방법 혹은 그 방법의 서순 자체를 알고리즘이라고 합니다.

컴퓨터 과학에서 알고리즘은 문제 해결을 할 수 있도록 하는 필수 요소일 뿐만 아니라 개발자에게는 사용자 (클라이언트)의 요구사항을 컴퓨터 기반의 언어로서 풀어낼 수 있도록 하고 나아가 더 효율적인 프로그램이 될 수 있도록 합니다. 수학으로 치면 풀이과정이며, 요리로 치면 레시피 같은 존재죠. 당연히 개발자의 실력 요소는 더 효율적인 알고리즘을 만드는 능력으로 대부분 평가합니다.
예를 들어, 최댓값을 찾는 프로그램에서는 최댓값 찾기 알고리즘이 있어야 할 것입니다.

더 복잡한 알고리즘들이 필요한 경우도 있겠죠.

그 외에도 내비게이션 프로그램에서 최단거리 찾기, 맛집 랭킹 분석 등 프로그램에 따라 무궁무진한 알고리즘들이 존재합니다.
자료구조의 기본
알고리즘은 데이터를 가지고 프로그램 안에서 효율적인 방법을 고안해 정보를 만들어 주는 기능을 한다고 했습니다. 그렇기에 알고리즘에 앞서 먼저 알아야 할 것은 자료구조입니다.
자료구조란 데이터의 논리적 관계를 표현하고, 조직화한 구조를 말합니다. 알고리즘 안에서 데이터들은 자료구조에 담겨 진행됩니다. 데이터들이 담긴 하나의 체계적인 구조체라고 봐도 됩니다. 자료구조에 대한 명확한 이해를 통해 적절한 자료구조를 선택하는 것은 알고리즘의 기본입니다. 자료구조의 종류들을 보면 그 정의를 함께 이해가 쉽겠습니다. 자료구조는 크게 다음과 같이 분류됩니다.

배열과 연결 리스트
배열 (Array)은 인덱스와 데이터를 같이 저장하여 (index, value) 인덱스를 통해 데이터를 찾아 들어가는 자료구조입니다. 논리적인 구조와 물리적인 구조가 일치하며, 그 구조 (순서)는 항상 유지됩니다.
데이터를 찾을 때는 인덱스를 통해 바로 찾아들어가기 때문에 효율적이나, 삽입/삭제 시에 배열 전체에 영향이 가는 작업이 필요하다는 비효율이 있습니다. 이를테면 삽입을 하게 되면 삽입 대상이 되는 인덱스 이상의 모든 노드를 한 칸식 뒤로 밀고 삽입해야 합니다. (삭제도 마찬가지)

배열이라고 하면 보통 1차원 배열을 말하나, 2차원 이상의 n차원 배열들이 존재하며 차원은 해당 배열에서 사용한 인덱스의 개수입니다.
연결 리스트 (linked list)는 인덱스 없이 별도의 링크 필드를 두고 바로 뒤의 요소와 연결되도록 하는 구조입니다. 논리적인 순서는 물리적인 순서와 다릅니다. 같을 필요가 없습니다. 다음 노드의 주소 값을 현재 노드에 저장해두기 때문이죠.
인덱스가 없기 때문에 데이터를 찾을 때 제일 앞의 요소부터 링크 필드를 타며 순차적으로 접근해야 하는 비효율성이 있습니다. 그러나 삽입 / 삭제 시 대상이 되는 위치의 링크 필드만 잠시 끊고 삽입 (삭제) 작업 후 다시 연결해주면 되기에 배열에 비해 효율적입니다.

링크드 리스트는 끝 노드와 첫 노드의 연결여부, 앞 노드와 뒤 노드의 양방향 연결여부에 따라 아래와 같이 분류됩니다.

스택과 큐
스택 (Stack)은 후입 선출 (Last In First Out, LIFO) 방식을 따르는 자료구조입니다. push();를 통해 스택에 데이터를 넣고 pop();을 통해 데이터를 꺼냅니다.

JAVA 개발자라면 JVM의 stack과 heap의 구조에 대해 아래에서 상세히 포스팅했으니 참고 바랍니다.
2022.01.26 - [개발/JAVA] - stack, heap (스택과 힙) - 자바의 메모리 런타임
stack, heap (스택과 힙) - 자바의 메모리 런타임
목차 자바의 메모리 영역 스택 (stack) 힙 (heap) 가비지 컬렉션 (Gabage Collection) 자바의 메모리 영역 자바의 메모리 구조는 크게 스택과 힙으로 나뉩니다. 스택 (stack) 기본 타입 (long, int, boolean,...)..
kghworks.tistory.com
큐 (Queue)는 선입선출 (First In First Out, FIFO) 방식을 따르는 자료구조입니다. put()으로 큐에 자료를 넣고 get()으로 자료를 꺼냅니다. front (head)는 자료를 꺼낼 수 있는 get() 위치를 의미하는데 처음에는 가장 앞부분을 가리키고 있습니다. rear (tail)는 큐의 제일 끝부분을 의미하고 자료를 넣을 수 있는 (put) 위치를 의미합니다.

트리와 그래프
트리 (Tree)는 하나 이상의 노드로 이루어진 유한 집합 (T)으로 다음 조건을 만족합니다.
- T의 원소 중 하나의 루트 노드가 존재한다.
- 루트 노드는 0개 이상의 자식 노드를 가진다.
- 루트의 자식 노드는 0개 이상의 자식 노드를 가지며 이를 반복적으로 자식 노드들에게도 적용된다.
- 자신을 포함한 자식 노드들의 집합은 하나의 서브 트리가 된다.

트리의 주요 용어들입니다.

차수 (degree)
노드의 차수란 해당 노드가 가진 서브 트리의 개수를 말합니다. 위에서 D 노드의 노드 차수가 3입니다. 트리의 차수도 있는데 트리의 모든 노드 중에서 최대 노드 차수 값을 말합니다. 위에선 A노드와 D노드 차수가 가장 큰 3이므로 위 트리의 차수는 3입니다.
레벨 (level)과 높이 (height)
트리의 한 세대별로 번호를 매겨 레벨 (깊이)이라고 합니다. 그 레벨의 최댓값은 트리의 높이가 됩니다.
숲
여러 개의 트리를 말합니다.
리프 노드 (leaf node, 단말, 터미널)
차수가 0인 노드를 말합니다. E, F, J가 리프 노드입니다.
비 단말 노드 (nonterminal node)
1개 이상의 차수를 가진 노드입니다. 리프 노드 외의 모든 노드가 비 단말 노드입니다.
부모 노드 (parent node), 자식 노드 (child node), 형제 노드 (sibling node)
부모 노드란 노드의 한 단계 상위 노드를 말합니다. C의 부모 노드는 A입니다. 자식 노드는 노드의 한 단계 하위 노드를 말합니다. B의 자식 노드는 E, F입니다. 형제 노드란 부모 노드가 같은 노드를 말합니다. G, H, I가 형제 노드입니다.
조상 (ancestor), 후손 (descendant)
조상이란 특정 노드를 기준으로 상위 레벨의 노드 중 자신의 부모 노드 혹은 부모 노드를 거쳐 올라갈 수 있는 모든 노드를 말합니다.(부모 노드의 형제 노드는 제외) J의 조상은 G, D, A입니다. 후손은 해당 노드의 자손 노드를 거쳐 내려갈 수 있는 모든 노드입니다. D의 후손 노드는 G, H, I, J입니다.
이진트리 (Binary Tree, BT)
모든 노드의 차수가 2 이하인 순서 트리를 말합니다.
- 레벨 I에서 최대 노드의 개수는 2^i
- 높이 h인 이진트리의 최대 노드 개수는 2^h -11
- n0 = n2 + 1 (n0 : 단말 노드수, n2 : 차수가 2인 노드의 수)
BT의 종류는 아래와 같습니다.

포화 이진트리 (Perfect Binary Tree, PBT)
PBT는 최대 레벨을 제외한 모든 노드가 2개의 자식 노드를 가집니다. 최대 레벨의 노드는 0개의 자식 노드를 가집니다. 트리의 노드 개수는 2^h-1 (h는 트리의 높이)
완전 이진트리 (Complete Binary Tree, CBT)
PBT에서 오른쪽부터 노드를 일정 부분 제거해나간 트리입니다. 비어있는 노드 오른쪽에 노드가 있다면 CBT가 아닙니다.
전 이진트리 (Full Binary Tree, FBT)
모든 노드가 0개 또는 2개의 자식 노드를 가집니다.
균형 이진트리 (Balanced Binary Tree, BBT)
왼쪽의 서브 트리와 오른쪽의 서브 트리의 높이 차가 1 이하인 트리입니다.
경사 이진트리 (Skewed Binary Tree, SBT)
SBT는 트리의 노드들이 왼쪽으로만 (혹은 오른쪽) 이어져있는 트리를 말합니다.
이진트리의 구현
모든 자료구조는 배열과 연결 리스트로서 구현이 됩니다. 이진트리도 마찬가지입니다. 이진트리를 1차원 배열로 구현해보겠습니다.

0 레벨부터 차례대로 배열에 넣었고 빈 노드에 대해서는 공란으로 구현됩니다. 배열의 사이즈는 트리의 레벨 기준 포화 이진트리일 때의 노드의 개수를 기준으로 합니다.
이번엔 연결 리스트로 구현했습니다. 각 노드의 양쪽에 본인의 자식 노드 링크 필드를 가집니다.

그래프 (Graph)
그래프는 정점 (V)의 집합과 각 정점이 이어진 간선 (E)의 집합이 모여있는 집합입니다. G = (V, E)

위 그래프를 집합으로 표현하면,
- 정점 집합 V(G1) = {A, B, C, D}
- 간선 집합 E(G1) = {(A, B), (A, C), (B, C), (B, D), (C, D)}
같이 표현합니다.
그래프의 종류는 아래와 같이 나눠볼 수 있습니다.

- 무방향 그래프 (undirected graph) : 간선의 방향성이 없음
- 방향 그래프 (directed graph) : 간선의 방향성이 있음
- 가중 그래프 (weighted graph) : 간선에 가중치를 둠. (내비게이션의 경로 등)
그래프의 주요 용어

인접 (adjacency), 부수 (incident)
두 노드가 간선으로 연결되어있을 경우 인접이라 합니다. 이때의 간선을 부수라고 합니다. G1의 A와 B는 서로 인접해있습니다.
부분 그래프 (subgraph)
원 그래프의 모든 노드를 포함하며, 간선을 0개 이상 뺀 그래프를 말합니다. G1의 서브 그래프 G1' = (V', E')이 주어졌을 때 G1'은 다음을 만족합니다.

- E'은 V'의 간선
- E'은 E의 부분집합
- V'은 V의 부분집합
경로 (path), 경로의 길이 (length)
한 개 이상의 간선으로 이어진 노드들의 시퀀스를 경로라 합니다. 경로에서 중복된 간선이 없으면 smple path라 하고, 노드가 겹치지 않을 경우 elementary 하다고 합니다. 경로의 길이란 경로에 포함된 노드의 개수를 의미합니다. G1 그래프를 기준으로 경로를 예를 들면 다음과 같습니다.
- 경로 1 (simple path) : [A, B, C, A]
- 경로 2 (simple path, elementary path) : [A, B, C, E]
차수 (degree)
노드에 연결된 간선 개수의 합입니다. G1의 C 정점의 차수는 3입니다.
사이클 (cycle), 루프 (loop)
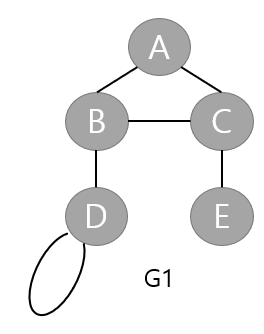
사이클은 경로의 시작 노드와 종료 노드가 같은 경로를 말합니다.
- 사이클 경로 : [A, B, C, A]
루프란 하나의 간선이 하나의 노드에만 부속해있을 때를 말합니다. (D는 루프 간선을 가짐)
연결 (connected)
두 노드를 연결하는 경로가 존재한다면 두 노드는 연결되었다고 말합니다. 무방향 그래프의 경우 모든 노드 쌍에 대한 경로가 존재하면 해당 그래프는 연결되었다고 말합니다. 방향 그래프의 경우 방향을 무시한 채로 모든 노드 쌍이 연결되었을 경우 연결되었다고 합니다. 방향 그래프에서 만일 두 노드 쌍이 서로가 시작점과 끝점이 돼줄 수 있다면 (서로에게 갈 수 있는 경로가 존재) 두 노드는 강하게 연결 (strongly connected)되어있다고 합니다.

G2의 C와 D는 강하게 연결됨.
- 경로 C-> D : [C, B, D]
- 경로 D > C : [D, C]
그래프는 인접 행렬과 인접 리스트로 구현이 가능합니다.

인접 행렬은 각 노드를 행과 열에 배치하고 노드 간의 간선이 있을 경우에만 1로 표시합니다. 행렬의 주대각 원소는 0입니다.
가중 그래프의 인접 행렬은 행렬 값에 가중치를 넣습니다. 주대각선은 마찬가지로 0이며, 노드 간의 길이가 2 이상일 경우 무한대로 표시합니다.
인접 리스트에는 가중치를 넣는 공간이 하나 더 필요합니다.

'Programming > Languages (Java, etc)' 카테고리의 다른 글
| 싱글톤 패턴 (Singleton pattern) (0) | 2022.05.10 |
|---|---|
| 알고리즘의 기본 - 시간복잡도 (0) | 2022.03.18 |
| js, css, html 파일 웹 브라우저 캐싱 방지 - 쿼리 스트링 (2) | 2022.03.04 |
| HTML의 개요 (0) | 2022.03.02 |
| [JAVA] Garbage Collection (가비지 컬렉션) (0) | 2022.02.16 |




댓글