https://kghworks.tistory.com/149
[Database] 인덱스 (Index) 1장 : 필요성과 기본 컨셉
특정 DBMS에 대한 인덱스 구조가 아닌 데이터베이스 시스템 자체에 대한 인덱스에 대해 정리한다. 기본 개념, 종류와 메커니즘에 대해 말하겠다. 전체적인 흐름은 데이터베이스 시스템 (Abraham Silb
kghworks.tistory.com
앞 포스팅에서 인덱스의 기본 분류는 Ordered Index (정렬된 인덱스)와 Hash Index (해시함수 기반 인덱스)로 나뉠 수 있다고 했다. 두 번째 포스팅에선 인덱스 종류 첫 번째 Ordered Index에 의 기본 성질과 어떤 종류들이 있는지 살펴본다. 인덱스의 종류 중 B+-Tree의 경우 내용이 많으므로 Ordered Index에 해당하지만 다음 포스팅으로 미룬다.
목차
- Ordered Index(순서 인덱스)
- Dense Index, Sparse Index
- Multilevel Index
- 인덱스 수정하기
- Nonclusterd index는 Dense index여야 한다
- 복합 인덱스
Ordered Index (순서 인덱스) - 정렬되어있는 인덱스
인덱스가 serach key를 기준으로 정렬되어 있으면 Ordered Idnex이다. 대부분이 인덱스에 해당한다. Hash Index를 제외한 모든 인덱스기 때문에 기본적으로 인덱스를 생각할 때 정렬되어 있다는 것을 깔고들어가는 이유기도 하다. search key를 record와 대응시키며, 파일은 1개 이상의 인덱스를 가지는 것이 가능하다.
Clustering Index (a.k.a Primary Index, Clustered Index)
실제 데이터 저장 순서 (물리적인 순서)가 search key의 정렬과 동일한 인덱스다. 즉, 인덱스의 순서가 실제 record 정렬과 동일한 인덱스다. 따라서 테이블 하나에 Clustering Index는 하나만 생성할 수 있다. PK에 인덱스를 생성하면 생성되는 것이 Clustering Index이다. 그래서 보통 PK에 대한 인덱스를 Primary Index, Clustering Index라 한다.
Clustering Index의 serach key는 PK가 아닐 수도 있다. PK가 아닌 속성에 대해 Clustering Index를 생성하면, PK에 대한 인덱스는 Nonclustering Index가 된다.
index-sequential file (인덱스에 의해 정렬된 파일)
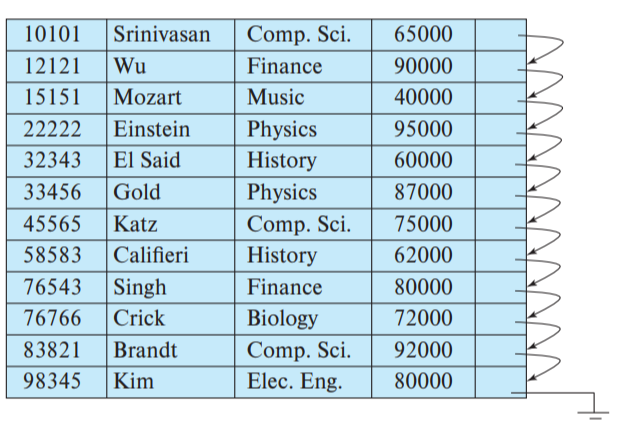
실제 파일 저장 순서가 index에 의해 정렬된 것을 말한다. 테이블에 Clustering Index가 있다면 해당 테이블은 index-sequential file이 된다. (다음에 설명할 B+-Tree의 경우 인덱스만 정렬, 파일은 정렬 안 함) 이는 오래된 인덱스 적용 방법이다. 인덱스의 정렬 기준을 그대로 파일을 물리적으로 정렬해서 저장한다.
위 그림은 instructor 테이블에 id 속성에 clustering index를 생성했을 때의 실제 record 모습이다. 실제 record의 정렬이 id 속성을 기반으로 되어있는 것을 확인할 수 있다.
Nonclustering Index (= Secondary Index, Nonclustered Index, 보조 인덱스)
인덱스의 Search key에 대한 정렬이 실제 record의 저장 순서와 다른 경우를 말한다. 보통 보조 인덱스라 부르며 테이블 하나에 Clustering Index는 하나만 존재 가능하기에 대부분의 인덱스가 보조 인덱스이다. 뒤에서 다시 말하겠지만 Nonclustering index는 반드시 Dense index (모든 record에 대해 1:1 매핑되는 index entry 존재)여야 한다. 그렇지 않으면 index entry의 value를 통해 record를 탐색할 수 없다.
Clustering Index와 PK
Clustering Index와 PK의 관계를 헷갈릴 수 있어서 보충 설명을 적어본다. Primary Index의 속성이 PK가 아닐수도 있는 경우는 어떤 경우가 있을까.
예를 들어, 주문 테이블에 주문 일자 속성에 Clustering Index를 생성했다고 가정하자. 그럼 주문번호 (PK) 속성에 대한 인덱스는 보조 인덱스 (Nonclustering Index)가 된다. 주문 테이블에 record는 Clustering Index에 따라 주문일자 순서대로 저장된다. 그렇다면 주문일자로 조회할 때 query 속도가 빨라질 수 있게 된다.
인덱스 구성요소 - Index Entry
인덱스의 요소 (element) 하나하나를 인덱스 엔트리 (entry)라고 한다. 이 인덱스 엔트리는 search key와 pointer (실제 record를 가리키는)로 구성된다. 만약 name에 대한 인덱스를 생성했으면 인덱스 엔트리 구성요소 하나를 열면 ("karina", <
karina" record를 가리키는 pointer>)로 구성된다.
(search key, pointer)
## name 속성에 인덱스를 생성하고, karina 인덱스 엔트리
("karina", <karina" record를 가리키는 포인터>)
그러나 index entry 가 가리키는 Record가 여러개일 수 있다. 이 때는 2가지가 가능하다
## 1. search key에 해당하는 모든 pointer 를 list로 보유
(search key, pointer list)
## 2. search key에 해당하는 record 중 첫번째 record를 가리키는 pointer
(search key, pointer)
Dense Index, Sparse Index
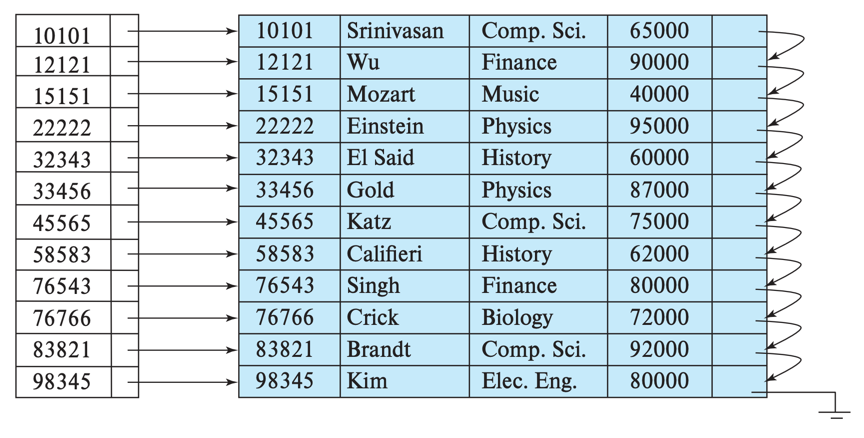
Clustering index는 Dense index (밀집), Sparse index (희소)로 나뉜다.
Dense index (밀집)
인덱스 엔트리가 record와 1:1 매핑되는 구조의 인덱스를 말한다. PK에 Clustering index가 생성되어 있다면 이는 Dense Index이다. 이러한 Dens Clustering index에서는 index entry vlalue에 첫 번째 record의 pointer만 저장한다. 다음 record는 순서대로 탐색하면 되기 때문이다.
Nonclustering Index에 대해 Dense index가 생성될 수도 있다. 고객 테이블에 주민번호 속성 (주민번호에 unique 제약조건이 있다는 가정) 에 인덱스를 생성하면 이는 Nonclustering index이자 (정렬이 다름) Dense index이다. Dense Nonclustering index에서는 index entry value에 pointer list를 저장해야한다.
Dense index는 테이블의 크기가 커지면 인덱스가 차지하는 공간이 커진다는 단점이 있다. (Space overhead)
## 1. Dense + Clustering index
<search key, 첫번째 record pointer>
## 2. Dense + Nonclustering index
<search key, pointer list>
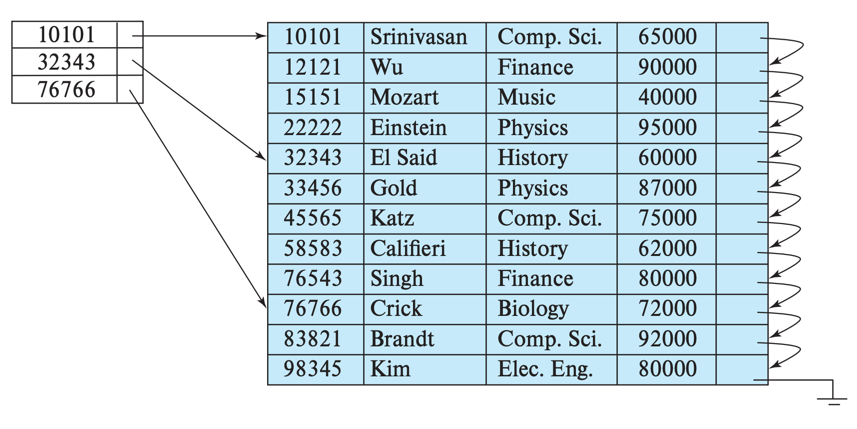
Sparse index (희소)
인덱스 엔트리와 record 수보다 적다. 반드시 clustering index여야 한다. 각 인덱스 엔트리는 해당하는 첫 번째 record를 가리키는 pointer만을 가진다. 만약 위 그림에서 id가 30000인 record를 찾는다면 30000보다 작은 인덱스 엔트리 중 가장 큰 인덱스 엔트리를 찾고, (인덱스 serach key = 10101) 해당 인덱스 엔트리의 포인터를 찾아들어가 해당 record부터 아래로 탐색한다. 이렇게 탐색하기 때문에 clustering index여야 한다. (index의 정렬 기준 = 파일 정렬 기준)
## Sparse index
<search key, 첫번째 record pointer>Dense index vs Sparse index
탐색 속도가 Dense index가 더 빠르지만 인덱스 공간을 더 많이 차지한다. (Access time) 반대로 Insertion, Deletion 작업은 Sparse index가 더 빠르다. (Space overhead)
Multilevel Index : 인덱스에 대한 인덱스
Dense index는 테이블이 커질수록 인덱스의 크기가 커진다. 인덱스의 크기가 작을수록 Access time이 줄어들 수 있다. 또한 인덱스가 커지면 메모리가 아닌 디스크에 저장되므로 인덱스 block을 fetch 하는 추가 시간이 필요해진다.
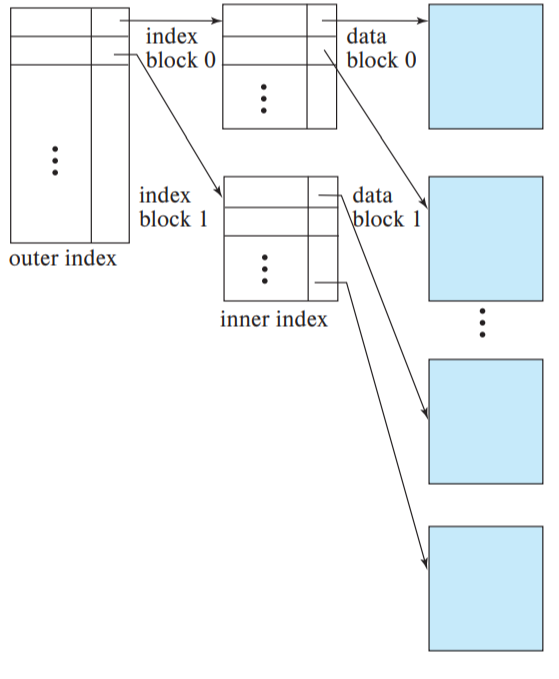
인덱스를 2개 이상의 level로 나누고 Sparse index를 통해 접근해 나가도록 하는 것이 Multilevel index이다. 인덱스에 대한 Sparse index를 생성하므로 인덱스에 대한 인덱스라고 볼 수 있다. 테이블이 커짐에 따라 비대해진 Dense Index를 쪼개고 Access time을 보장할 수 있다. 각 level 별로 인덱스는 마찬가지로 정렬되어 있다.
인덱스 수정하기 - 삽입, 삭제
인덱스는 테이블에 record가 수정되면 수정되어야 한다.
INSERTION (e.g. name = 'karina')
insert가 발생하면 해당 record의 search key를 사용해서 인덱스를 탐색한다. 예를 들어, Student record가 들어왔을 때 Student 테이블에 name을 속성으로 인덱스가 있다면, name을 search key로 해당 인덱스를 탐색한다. 그다음부터는 Dense index, Sparse index가 각자 동작이 다르다. (여기에서는 name = 'Karina'인 record가 insert 되었다고 가정)
Desne index는 search key가 'Karina'인 인덱스를 찾고, 없으면 index entry에 추가한다. 만약 이미 'karina'인 인덱스가 존재한다면, pointer 리스트에 추가하던가, 적절한 위치에 record를 삽입하던가 한다. (clustering, nonclustering에 따라)
Sparse index의 경우 새로운 block을 생성해야 하면 새로운 block의 첫 번째 <'karina', pointer>로 인덱스를 생성한다. 만약 해당 'karina'가 이미 존재하는 block의 가장 작은 값이라면, insert 된 record를 가리키도록 index entry value를 수정한다. 둘 다 아니면 인덱스에 수정이 없다. (name='karina'인 인덱스 block을 생성 안 하고, 이미 존재하는 block의 최저값도 아님)
Deletion (e.g. name = 'karina')
먼저 삭제할 record를 찾는다. 그다음 Dense, Sparse에 따라 다르다.
Dense index는 search key가 'karina'인 record가 하나뿐이면 index entry를 제거한다. 만약 record가 여러 개라면, pointer list에서 제거하던가, 삭제된 record를 가리키는 어떤 record의 pointer를 제거하던가 한다. (clustering, nonclustering에 따라)
Sparse index는 search key가 'karina'인 index entry가 없으면 변경이 없다. 만약 있다면 name='karina'인 record가 하나라면 index entry를 제거하고, 2개 이상이면 삭제된 record를 가리키는 어떤 record의 pointer를 수정한다.
Nonclusterd index는 Dense index여야 한다
보조 인덱스는 반드시 Dense index여야 한다. 만일 보조 인덱스가 Sparse index라면, 인덱스에 해당하는 record가 2개 이상일 때 모두 탐색할 수 있는 방법이 없다.
보조 인덱스가 후보키에 형성되어 있다면 (e.g. 회원 테이블의 주민번호 속성에 대한 인덱스) 마치 dense clustering index처럼 보일 수 있다. 그러나 회원 테이블은 해당 테이블의 PK로 정렬되어 있을 것이므로 실제 파일 정렬에 차이가 있다.
반대로 보조 인덱스가 후보키가 아닌 속성 (e.g. 회원 테이블의 이름 속성)에 형성되어 있어도 dense index여야 한다. 만약 sparse index로 형성되어 첫 번째 record의 pointer만 가지고 있어도 그다음 record는 file 알 수 없는 어딘가에 있기 때문이다. 이렇게 중복된 search key에 대해 인덱스 엔트리를 형성하는 것 (e.g. <'karina', pointer001>, <'karina', pointer002>,...)을 nonunique search key라고 한다.
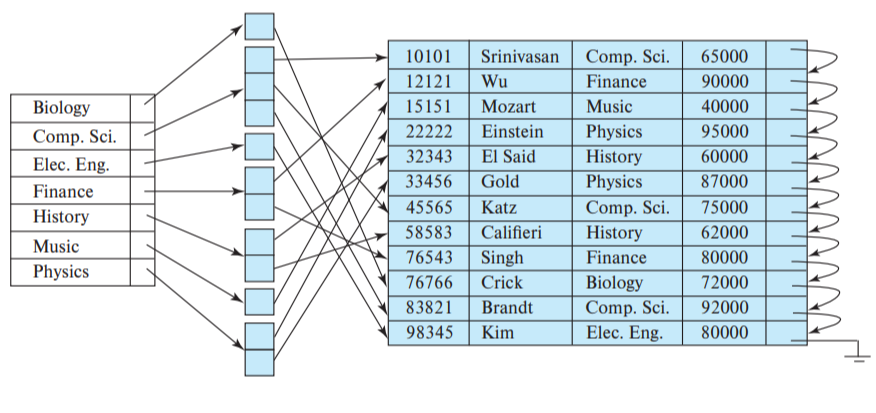
nonunique search key는 space overhead가 떨어진다. 효과적으로 구현하는 방법이 없을까. 위 그림처럼 각 index entry value가 자신의 search key에 해당하는 reocord pointer가 담긴 bucket을 가리키게 만든다. 그렇다면 record 숫자만큼 index entry를 생성하지 않아도 된다. (space overhead 극복) 그러나 access time은 늘어나고, 마찬가지로 search key에 대한 중복이 늘어날수록 space overhead는 증가한다. insertion / deletion time도 더 늘어날 수 있으니 select와 DML 비율을 고려하여 설계해야 한다.
복합 인덱스 (Indexes on Multiple keys)
index entry를 2가지 이상의 search key로 구성한 인덱스를 말한다. 예를 들어, 학생 테이블에 이름, 나이, 학년 속성으로 복합 인덱스를 생성했다면, 인덱스의 정렬 우선순위는 search key 이름 > 나이 > 학년 순으로 지정하게 된다. 다음은 해당 인덱스에 대한 index entry 정렬 순서에 대한 예시이다.
- <강감찬, 13, 5, pointer001>
- <강감찬, 13, 6, pointer131>
- <세종대왕, 10, 3, pointer019>
- ...
B+-Tree 인덱스에 대한 설명은 아래 포스팅에서 이어진다.
https://kghworks.tistory.com/151
[Database] 인덱스 (Index) 3장 : B+-Tree Index 기본
https://kghworks.tistory.com/150 [Database] 인덱스 (Index) 2장 : Ordered Index https://kghworks.tistory.com/149 [Database] 인덱스 (Index) 1장 : 필요성과 기본 컨셉 특정 DBMS에 대한 인덱스 구조가 아닌 데이터베이스 시스템
kghworks.tistory.com
참고
https://product.kyobobook.co.kr/detail/S000001693775
데이터베이스 시스템 | Abraham Silberschatz - 교보문고
데이터베이스 시스템 |
product.kyobobook.co.kr
'Engineering > Database System' 카테고리의 다른 글
| [Database] 인덱스 (Index) 4장 : Hash Index (0) | 2023.10.20 |
|---|---|
| [Database] 인덱스 (Index) 3장 : B+-Tree Index 기본 (0) | 2023.10.19 |
| [Database] 인덱스 (Index) 1장 : 필요성과 기본 컨셉 (0) | 2023.10.12 |
| [개발일지] 채번(採番) 개발하기 (0) | 2023.10.05 |
| [DBMS] PK 선정 전략 - surrogate key와 natural key (0) | 2023.01.15 |




댓글