채번(採番)이란 번호를 딴다는 의미로 번호표의 목적으로 DBMS에서 PK 혹은 고윳값을 부여할 때 사용하는 용어다. 일본말이라고 함. 채번되는 값이 업무적으로 의미 있는 값이건, 단순 고윳값이건 각각의 목적이 충분히 존재한다. 나의 경우 고객에게 노출하는 값은 아니었지만 고윳값을 가지면서 SELECT도 가능해야 했다. (이건 이후에 후술)
웹서비스에서 채번 하는 업무는 꽤 있다. (계좌번호, 자동차 번호판 등) 단순히 sequence (ORACLE), auto_increment (MYSQL) 등 사용해 채번 할 수 있지만 그 이상의 요구사항이 존재한다. 채번 결과가 어떤 포맷을 유지해야 한다던지 등..(계좌번호, 자동차 번호판 등)
이번 포스팅에서는 채번 프로세스를 어떻게 개발하게 되었는지 과정과 결과를 소개해본다. 마지막에는 인스타그램의 채번방식 (2012년 포스팅)을 염탐해 본다.
목차
- 채번 요구사항
- 채번하는 여러 방법
- 부가적인 고민들
- [탐구] Instagram의 채번 방식 (Sharding 환경)
개발 환경
- Java & Spring Framework
- Oracle
채번 요구사항
bulk isnert 개발 중 테이블에 논리적으로 transaction ID를 부여해줘야 하는 일이 생겼다. bulk insert 시 데이터베이스의 부하를 덜기 위해 일정 사이즈마다 commit을 하는데 예외 발생 시 비즈니스 전체를 rollback 하기 위한 논리적인 트랜잭션 단위를 부여하기 위함이다. 다음이 요구사항이다.
- HTTP 트랜잭션 별로 unique 한 값을 DB 컬럼에 넣어주어야 함
- 채번 된 컬럼으로 select 성능 보장 필요 (예외 발생 전체 rolback 시)
채번 하는 여러 방법
채번하는 방법은 인터넷에도 검색하면 여러 가지가 나온다. 여러 방법이 있지만 그 공통점이자 핵심은 고윳값이다. 특정 단위 별로 다른 값들과 구분되는 unique 한 값을 만들어내는 것이 핵심이다.
방법 1. max() + 1
가장 단순한 방법으로, 대상이 되는 테이블의 max값을 가져와 1 증분 시켜 채번하는 방법이다.
SELECT MAX(채번_대상_컬럼) + 1 AS "채번_결과"
FROM 대상_테이블
이대로만 하면 동시성 제어가 전혀 안된다. 두 세션이 거의 동시에 채번값을 select해서 (이 때, 두 세션이 같은 채번값을 가지고 있음) insert 한다면 데이터 정합성이 틀어지는 문제가 발생한다. 따라서 동시성 제어를 위한 추가적인 방법이 필요하다. 해당 업무에 java synchronized 키워드를 추가할 수 있지만, 이는 전체 application 성능에 저하를 초래할 수 있다.
방법 2. 채번 테이블
별도의 채번 전용 테이블을 생성한다.
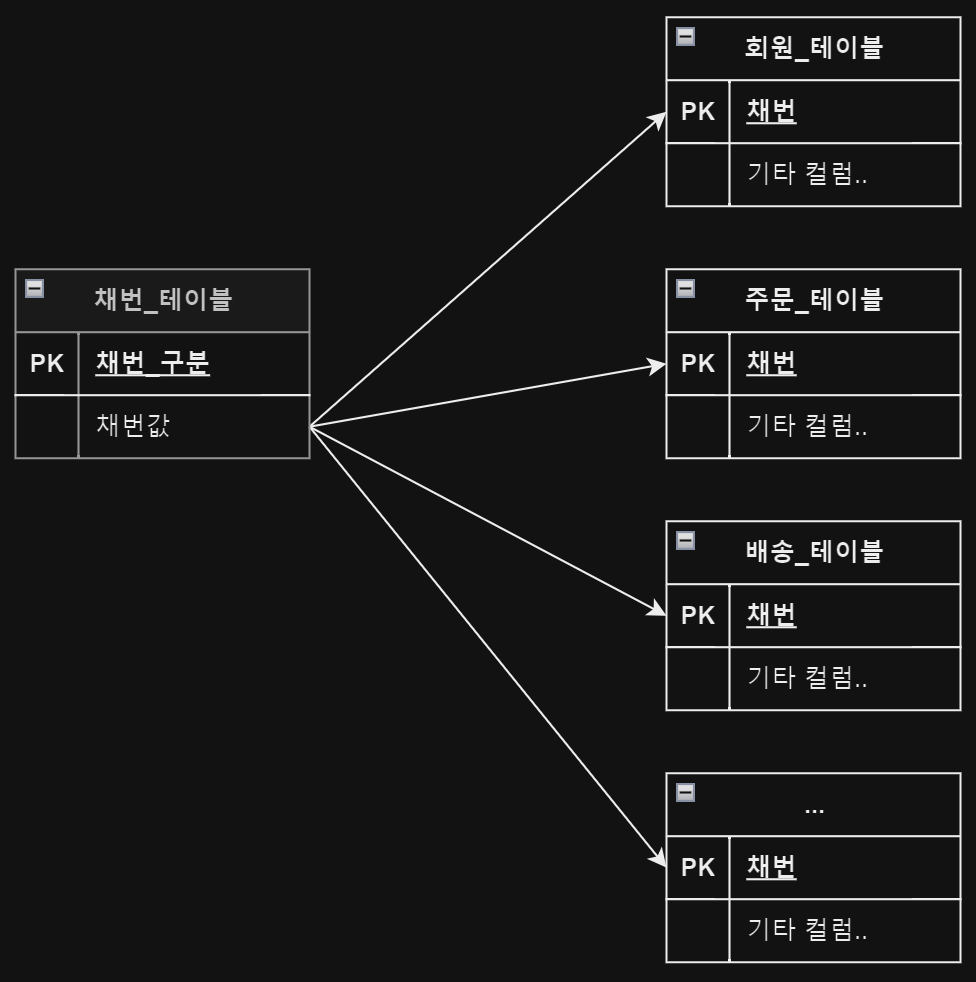
채번 테이블을 생성해 두고, 채번이 필요할 때마다 채번 테이블에 row lock (ORACLE)을 걸어 채번값을 생성한다. 데이터의 동시성 제어를 철저히 DBMS에 위임하는 방식이다.
- 채번 값 UDPATE (1 증가)
- 대상 테이블에 INSERT
- COMMIT
위 1~3 단계에 걸쳐 채번 테이블에는 row lock이 걸려있어 대상 테이블에 INSERT 하기 위한 세션이 많아진다면 lock waiting sesison이 쌓이게 된다. 1번 이후에 바로 채번 테이블만 COMMIT 해주어 채번 테이블의 row lock을 먼저 해제해 주는 방법으로 해소가 가능하다. 또 다른 단점으로 채번이 필요한 대상 테이블이 많아질 때마다, 채번 테이블이 거대해질 수 있다.
방법 3. DBMS 제공 기능 활용 (SEQUENCE, AUTO_INCREMENT)
내가 선택한 방법이다. 현재 Oracle RDBMS를 사용하고 있으므로 시퀀스 객체를 사용하여 채번 하는 방식이다. 경합상황에서의 중복 에러도 없고, lock에 대해 고민하지 않아도 된다. 그러나 sequence는 cache, RAC 구조 등의 조건에서 중간마다 값이 빌 수 있다. 값이 반드시 순차적이고, 빈값이 없어야 하는 환경에서는 추가적인 업무 로직이 필요해진다. 나의 경우 채번 값 중간이 비어도 비즈니스에 문제가 없다고 판단하여 sequence를 선택했다.
시퀀스의 장점은 다른 값들과 적절히 조합이 가능하다는 것이다.
SELECT 내가_만든_시퀀스.NEXTVAL
FROM DUAL;
위처럼 가져온 고윳값을 다른 값들과 조합하여 유의미한 값을 생성해 낼 수도 있다.
MySQL의 경우 auto_increment 속성을 제공하지만, 이는 데이터베이스 테이블의 특정 컬럼에만 가능한 기능이다. 나의 경우 MySQL이라면 auto_increment를 사용하고 추가 요구사항이 있다면 별도의 채번 테이블을 사용해야 할 것 같다. 일단 난 Oracle
부가적인 고민들
단순히 형태에 상관없이 고윳값만 필요하다면, 시퀀스. nextval로 계속 사용하면 된다. 그러나 실제 업무에는 여러 제약사항이 있다.
채번 데이터의 컬럼사이즈는 유한하다
채번한 데이터가 들어갈 컬럼의 사이즈는 무한하지 않다. sequence를 무턱대고 증가시키며 insert했다가는, 컬럼 사이즈에 넘쳐 ORA-12899을 맞는다. 따라서 sequence에 cycle, maxvalue를 지정해 주었다.
CREATE SEQUENCE 시퀀스명
START WITH 1
INCREMENT BY 1
...
MAXVALUE 999 -- 최댓값 : 999 (세자리)
CYCLE; -- 최대값에 도달하면 1부터 다시 시작
또한 sequence가 순환하면 중복이 발생할 수 있다. 따라서 적절하게 가공을 해주어야 하는데 나의 경우 하루 트랜잭션 수를 감안하여 sysdate, 난수를 첨가했다.
SELECT TO_CHAR(SYSDATE, 'YYYYMMDD') -- 현재 날짜
|| TO_CHAR(생성할_시퀀스.NEXTVAL, 'FM000') -- 시퀀스
|| TO_CHAR(DBMS_RANDOM.VALUE(1, 1000), 'FM999') -- 난수 (1 ~ 999)
FROM DUAL;
날짜 정밀도를 YYYY-MM-DD로 사용했기 때문에 하루에 최대 999개의 트랜잭션 (HTTP 트랜잭션)이 들어온다고 감안했다. 하루에 트랜잭션 수가 999번이 넘어 sequence 사이클이 한번 순환된다면 중복이 발생하므로 뒤에 세 자리 난수를 추가했다. 하루 999번까지는 고윳값을 보장한다. 운영 중 트랜잭션 규모가 늘어나면, 시퀀스의 최댓값을 999 이상으로 조정하면 중복을 회피할 수 있다.
채번 업무를 어디에 구현할 것인가. Java? Oracle?
채번값을 생성하는 sql문은 완성되었다. 이제 sql문을 어디에 위치할지가 문제다.
- Java
- Oracle Funciton
둘 다 장단점이 있다. Java에 두면 DB에 덜 의존적인 방법으로 소스 형상관리 범위에 포함되고, 개발자가 더 친숙할 수 있다는 장점이 있다. 그러나, 트랜잭션 규모가 늘어 급하게 시퀀스 값을 늘린다건가 하는 긴급 조치 시에 WAS 재기동이 동반되어 대응이 느리다는 단점이 있다.
Oracle Function에 두면 대응이 빠르다. 관리 포인트도 하나로 통합된다. 그러나 소스의 형상관리가 잘 되지 않고, 실수로 compile 되는 순간 반영되기 때문에 관리 리스크가 있다.
나는 Oracle Function에 두었다. 왜냐면 이 sql을 호출할 was가 1개 이상이었기 때문이다. 같은 sql문을 여러 서버에 흩뿌려놓아야 하는데, 그만큼 관리 포인트가 늘어나게 되는 추가 단점이 있다. 업무별로 컨테이너를 나누는 요즘 유행하는 아키텍처가 아니었기 때문에 이러한 단점이 있었다. 암튼 그래서 Oracle Function에 두고 호출하기로 했다.
개인적으로 이런 경우 DB Function을 선호한다. 관리 포인트를 하나로 모으고, DB에 로직을 관리하는 것이 여러 리스크가 있음에도, 이 경우 자주 바뀌는 로직이 아니다. 개발자들도 역으로 WAS에서 SELCT 문으로 fucntion을 호출만 하면 되어서 크게 불편함 없다.
[탐구] Instagram의 채번 방식 (Sharding 환경)

https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c
Sharding & IDs at Instagram
With more than 25 photos and 90 likes every second, we store a lot of data here at Instagram. To make sure all of our important data fits…
instagram-engineering.com
2012년도 포스팅이지만 빅테크 기업의 채번 로직을 엿볼 수 있어서 간단히 정리해 본다. 기본 구조는 나의 구현과 비슷하나, 논리/물리적 sharding 환경인 점이 다르다.
채번 요구사항 (2012 당시)
포스팅에서 예시로서 든 데이터로 보인다.
- PostgreSQL
- 수천 개의 논리적 sharding DB와
- 그보다 적은 물리 sharding DB 서버
- 채번 값은 시간 순 정렬이 가능해야 함
- 크기는 64bit
- 간단한 구현 (외부 서비스 의존도 최소화)
옵션 1. web application에서 구현
- uniqueness 보장을 위해 최소 96bit 필요
- 순수 UUID는 시간 정렬 불가능
옵션 2. 외부 서비스 (e.g. Twitter Snowflaker)
- 외부 서비스 의존도 증가
옵션 3. DB ticket server
- 쓰기 병목 (bottle neck) 가능성
- 추가 machine (e.g. EC2 instance) 필요
- 단일 서버면 리스크 존재, 2개 이상의 서버이면 유일성 보장 불가
Instagram의 선택
- 41bit 정밀도의 miliseconds +
- 13bit의 logical shard ID +
- 10bit의 auto incrementing sequence (각 shard 별)
즉 millisecond 마다 각 shard 별로 10bit의 sequence 수만큼 채번 가능
채번 PL/PGSQL
CREATE OR REPLACE FUNCTION insta5.next_id(OUT result bigint) AS $$
DECLARE
our_epoch bigint := 1314220021721;
seq_id bigint;
now_millis bigint;
shard_id int := 5;
BEGIN
SELECT nextval('insta5.table_id_seq') %% 1024 INTO seq_id;
SELECT FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000) INTO now_millis;
result := (now_millis - our_epoch) << 23;
result := result | (shard_id <<10);
result := result | (seq_id);
END;
$$ LANGUAGE PLPGSQL;
참고
https://dataonair.or.kr/db-tech-reference/d-lounge/expert-column/?mod=document&uid=51981\
DB 성능 제고를 위한 채번의 이해와 방식별 장단점 비교
◎ 연재기사 ◎ ▷ 물탱크 구조로 알아본 오라클의 블록 옵션 ‘PCTFREE와 PCTUSED’ ▷ 이산가족 찾기 생방송을 통해 배우는 DB 원리 ▷ 개발자에게 맞는 DB 공부방법 찾기: 물리적 분류와 논리적 분
dataonair.or.kr
https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c
Sharding & IDs at Instagram
With more than 25 photos and 90 likes every second, we store a lot of data here at Instagram. To make sure all of our important data fits…
instagram-engineering.com
'Engineering > Database System' 카테고리의 다른 글
| [Database] 인덱스 (Index) 2장 : Ordered Index (순서 인덱스) (0) | 2023.10.12 |
|---|---|
| [Database] 인덱스 (Index) 1장 : 필요성과 기본 컨셉 (0) | 2023.10.12 |
| [DBMS] PK 선정 전략 - surrogate key와 natural key (0) | 2023.01.15 |
| [ORACLE] Lock 1편 - Lock의 개념과 매커니즘 (0) | 2022.10.12 |
| DISTINCT, GROUP BY 무엇을 쓸까 (1) | 2022.09.26 |




댓글