
목차
- Streaming Data
- Streaming Data를 쿼리하는 방법
- Algebraic Operations
- Publish / Subscribe system
- [참고] 트위터의 데이터 처리 방식
Streaming Data : 지속적인 데이터 흐름
웹 서비스에서의 데이터는 주로 데이터베이스 시스템에서 관리된다. Relational Database Management System (RDBMS, 관계형 데이터베이스)가 대표적이다. 데이터베이스에 저장된 데이터를 불러오기 위해 많은 client들이 질의 (query)하는데 이 질의를 지속적으로 (혹은 주기적으로) 해야 하는 데이터들이 있다. 예를 들면, SNS 게시글은 데이터가 추가될 때마다 엄청난 질의가 들어올 것이다. 호날두가 인스타그램에 글을 올리면 해당 게시글의 SELECT 쿼리가 얼마나 많이 발생할 것인가?
However, there are many applications where queries need to be executed continuously, on data that arrive in a continuous fashion. The term streaming data refers to data that arrive in a continuous fashion. Many application domains need to process incoming data in real time (i.e., as they arrive, with delays, if any,guaranteed to be less than some bound).
- Database System Concepts (저 : Abraham Silberschatz) > 10.5 Streaming Data (529p)
주기적으로 끊임 없이 질의가 들어오는 데이터는 지속적으로 흐른다고 볼 수 있고, 이를 Streaming data라고 정의한다. 오늘날의 많은 Application 도메인들은 이러한 실시간으로 들어오는 데이터에 대한 처리를 요구한다.
Streaming Data를 사용하는 도메인 예시
- Stock market (주식 시장) : 지속적으로 거래 data가 생산되어 거래 처리 system에 요청
- E-Commerce : 거래 시퀀스에 의해 거래 데이터가 stream을 이룸 (주문 -> 결제 -> 배송)
- Sensors (센서) : 센서로부터 data를 주기적으로 생산함, 빌딩, 공장, vehicle 등
- Social Media (SNS) : 유저의 메시지가 적절히 라우팅 필요 e.g. 친구에게? 모두에게? Facebook, Twitter
Streaming data의 특징
Streaming Data는 끝이 없다. 데이터의 끝 (종료), 마지막 데이터와 같은 것이 불가능하고, 단어 (streaming) 그대로 끝없이 흐른다. 예를 들면, SNS에서 유명 연예인의 게시글 데이터에 끝이 있지 않다. 연예인은 오늘내일 계속 게시글 데이터를 끝없이 만들어낼 수 있다.
따라서 Streaming Data에 대한 질의 결과는 최종 결과가 아니다. 연에인의 인스타그램에 들어가서 게시글 페이지에 들어가면 그 순간까지의 모든 게시물을 볼 뿐, 연예인이 게시글을 쓰는 순간 게시글 홈페이지에는 새로운 게시글이 추가되어야 한다.
Streaming data를 처리할 때 특정 범위로 tuple을 묶어야한다. 이 단위를 window라 한다. 이 범위의 기준은 시간일 수 있고, 숫자가 될 수 있다. SNS 시스템으로부터 게시글 데이터가 끝없이 생산될 때 특정 window로 묶어 다음 처리 (팔로워에게 push 등) 하는 것과 같다.
Streaming Data를 쿼리하는 방법
Streaming data가 필요한 시스템은 streaming data를 쿼리 해야 한다. 끝없이 생산되고 흐르는 데이터를 어떻게 쿼리 할 수 있을까. 크게 네 가지 방법이 있다.
Continuous query (지속적으로 쿼리하기)
Streaming data를 데이터베이스에 곧장 저장(적재)한다. 즉 하나의 DB 저장소로 간주한다. 그리고 끊지 않고 계속해서 쿼리를 반복한다.
예를 들면 특정 RDBMS 테이블에 새롭게 Insert 된 데이터를 보려면 어떻게 할까? 1초마다 계속해서 Select 하면 된다. 그러나 이러한 방법은 집계데이터를 보여주는 애플리케이션에는 매우 비효율적이다. 집계데이터를 갱신하기 위해 계속해서 데이터 read가 발생하기 때문이다. 새로 유입된 사용자수를 알기 위해 1초마다 사용자 테이블에 SELECT Count(*)을 한다? 매우 비효율적이다. 포스팅 마지막에 트위터의 예시를 통해 확인할 수 있다
Stream query language 사용
streaming data에 특화된 query를 사용하는 방법이다. 앞에서 말한 window를 둘 수 있다. 예를 들어 정시마다 streaming data를 취합하여 새로운 tuple을 생산해 내는 식이다.
Algebraic Operation (가장 많이 사용되는 방법)
2x +5와 같은 표현식, 연산이 Algebraic Operation이다. streaming data가 input을 통해 operator (연산시스템)에게 전달된다. operator는 다른 operator에게 전달할 수도 있고, 특정 시스템 (DB 등)에 저장할 수 있다.
Pattern matching (Complex Event Processing, ECP)
먼저 Pattern matching language를 정의해서 사용자에게 제공해야 한다. 그다음 Streaming Data를 추적하는 system이 특정 패턴에 맞는 tuple을 발견하면 그에 걸맞은 다음 action을 취한다. Complex Event Processing (CEP)라고도 한다. e.g. Oracle Event Processing, Microsoft Streaminsight, FlinkCEPI
Algebraic Operations : Apache Storm, Kafka
SQL은 Relational DB에 적합한 언어이다. 그러나 Streaming Data는 RDBMS에 적합한 데이터가 아니니 애초에 SQL로 Streaming Data를 다루기에는 한계가 있다.
앞에서 말한 쿼리 방법 중 가장 널리 사용되는 Algebraic Operation으로 다룰 수 있다. 각 시스템을 하나의 Algebraic Operator로 간주한다. streaming data는 operator의 input으로서 또 다른 operator (시스템)에게 라우팅된다. 다시말하면 Operator는 input을 consume하여 또다른 operator에게 전달한다. (= Operator 간에 데이터가 계속 흐른다) 당연히 고가용성(HA), fault-tolerant 한 라우팅을 구현해야 한다. Apache Storm과 Apache Kafka가 많이 쓰인다.

Directed Acyclic Graph (DAG)
각 Operator를 node로 간주하고 node 간의 edge는 Streaming Data의 이동선을 나타낸다. data-sink node는 Streaming System의 종착지로서 저장소일 수 있고, 또 다른 시스템에 전달될 수 있는 노드이다. 대표적으로 Apache storm이 있다.
Publish-Subscribe system (pub-sub)
Publisher는 data를 특정 topic으로 발행한다. Subscriber는 특정 toopic을 구독한다. Tuple은 특정 topic에 속한다. 대표적인 시스템이 Apache Kafka이다. Kafka는 데이터를 disk에 보관하고, Subscriber가 없어도 특정 기간 동안 Disk에 저장해 둔다. Subscriber (Consumer)는 실패 (fail)이 일어나도 Disk 저장기간 동안은 얼마든지 재시도가 가능하다. 그 외에도 Redis, RabbitMQ 등이 있다.
Publish / Subscribe system (Kafka 기준)
Pub/Sub 시스템을 좀 더 살펴보자. Kafka를 기준으로 Kafka 클라이언트는 크게 2가지로 분류된다.
- Publisher (producer, sender, wirter) : Message (data)를 발행. subscriber에게 직접 (direct) 전송 안 함
- Subscriber (consumer, recevier) : Message (data)를 읽음, 소비
예를 들어 특정 모니터링 정보를 수집하는 애플리케이션이 있다고 해보자. 그럼 아래 그림처럼 하나의 Metrics server와 각 모니터링 정보를 전송하는 1개 이상의 Frontend server가 있을 것이다.

특징은 관계가 있는 서버가 서로 강하게 결합 (의존, direct)되어있다는 것이다. 점차 모니터링 정보를 전송하는 서버가 늘어나고, 모니터링 정보에도 종류가 다양해져 수집 서버 또한 다양해졌다고 해보자.
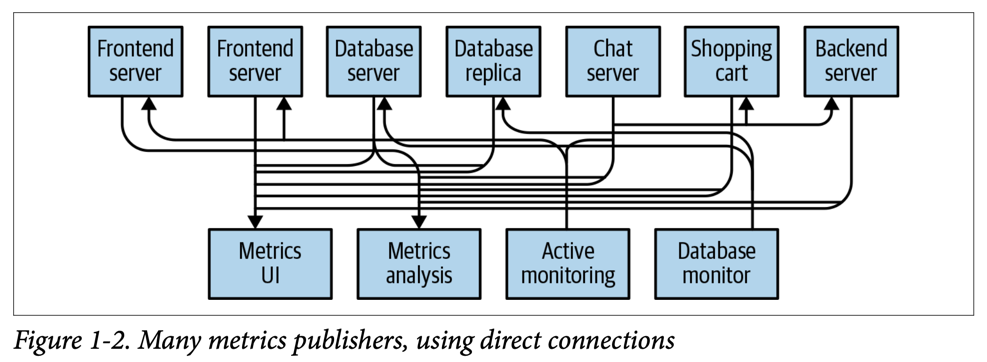
대혼돈이다. 서버와 서버가 모두 강하게 결합되어 있고 전체 아키텍처는 매우 혼잡해졌다. 위 구조에서 특정 서버에 수정이 필요하다면 수정에 따른 그 영향력을 쉽게 파악할 수 있을까? 게다가 연관된 서버는 모두 직접 연결되어 있으므로 영향범위를 잘못파악해 연관 서버를 놓친다면 해당 서버에는 큰 피해가 갈 것이다. 여기서 Pub/Sub System (message broker)이 등장한다.
서버 수는 그대로지만 데이터 흐름이 단순해졌다. 모니터링 정보를 전송하는 서버는 Pub/Sub 시스템에 데이터를 발행하고, 모니터링 정보 수집서버는 Pub/Sub 시스템으로부터 데이터를 소비한다.
이 예시는 Kafka를 개발한 LinkedIn의 일화 그대로다. LinkedIn은 user activity (사용자 활동), system metric (시스템 사용률)을 추적하기 위한 시스템을 구축했으나 예시처럼 복잡도가 증가하게 되어 별도의 전용 데이터 파이프라인을 구축했고 그것이 Pub/Sub 시스템 kafka이다. Kafka는 오픈소스로 2011년 Apache에 넘어가 현재는 여러 기업 (LinkedIn, Confluent)들에서 프로젝트를 관리하는 대표적인 Pub/Sub 시스템이다.
Producer (Kafka의 publisher)
message를 생성 (publish)하는 클라이언트다. message는 특정 topic에 속하며, Kafk Pub/Sub 시스템 전반적으로 topic이 파티셔닝 되어있다. Publisher는 특정 Partition에 직접 메시지를 생성할 수도 있다. Kafka에서는 producer라고 한다.
Consuemr (Kafka의 subscriber)
message를 읽는 클라이언트다. 다른 Pub/Sub 시스템에서는 subscriber, reader 등으로 표현하고, Kafka에서는 consumer라고 한다. 각 파티션에 적재된 데이터를 FIFO 알고리즘으로 읽는다. 하나의 파티션은 오직 하나의 consumer로부터 읽을 수 있으며, 이를 consumer의 ownership이라 한다.
Broker (Single-Kafka server)
producer로부터 메시지를 받고 consumer에게 제공하는 Kafka 단일 서버다. 하드웨어 퍼포먼스에 따라 Broker 하나가 1초에 수천 개의 parittion, 수만 개의 메시지를 핸들링할 수 있다.
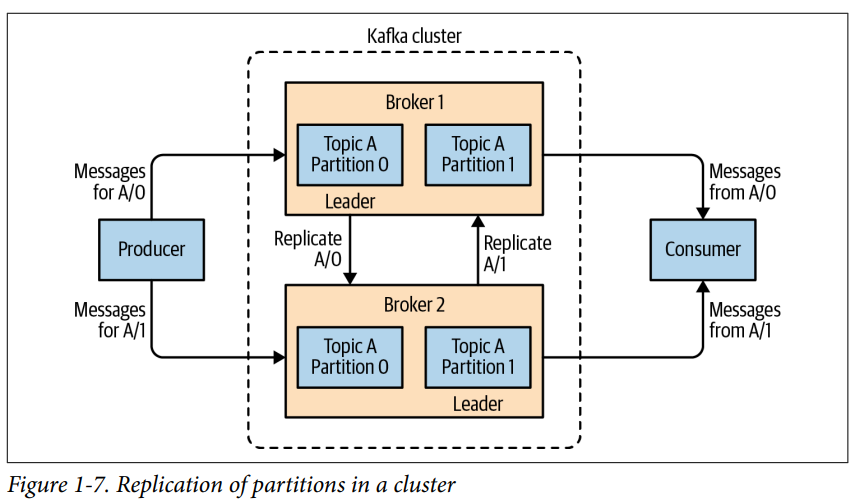
Kafk cluster (Broker 집합)
여러 개의 Broker를 클러스터링 할 수 있다. (아래 그림 참고) cluster 중 하나의 broker를 컨트롤러로 자동으로 선정한다. 컨트롤러는 관리자로서 partition을 broker에 할당, 각 broker에서 발생하는 장애를 모니터링한다.
[참고] 트위터의 데이터 처리 방식
Twitter 서비스는 크게 2가지 액션을 이룬다.
- Post tweet : 사용자가 메시지를 팔로워들에게 publish 한다. (평균 4.6K req/sec, 피크 12k req/sec)
- Home timeline : 팔로워들의 홈 화면에서 팔로우 사용자들의 트윗을 조회한다. (300K req/sec)
이 업무를 구현할 수 있는 방법은 어떤 것들이 있을까
방법 1. Global DB에 Insert 하고 조회
사용자가 트윗을 작성하면 트위터 Global DB에 Insert 한다. 팔로워들이 홈화면에 진입할 때마다 Global DB로부터 팔로우들의 데이터를 Select 한다.
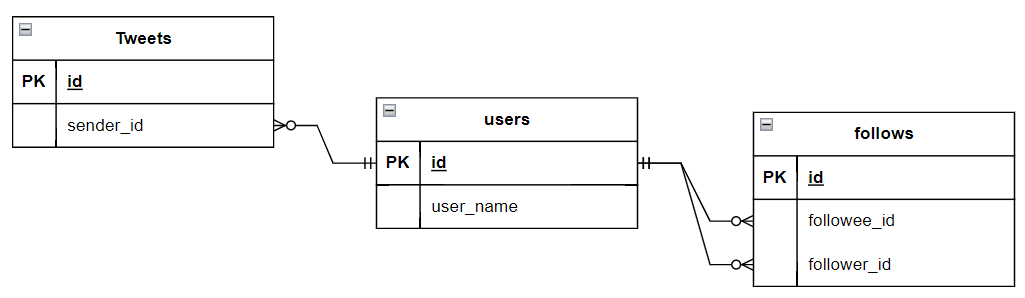
SELECT tweets.*, users.*
FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = {current_user}
만약 탑 인플루언서가 게시글을 등록하면 어떻게 될까? 예를 들어 팔로워가 1억 명인 연예인이 트윗을 했다고 가정해 보자. 그럼 tweets, users, follows 테이블에 위 SQL을 통해 최소 1억 번의 Read가 들어온다. 엄청난 부하다.
초기 버전의 트위터는 이 방법을 사용했다. 그러나 시스템이 커질수록 홈 화면에서 들어오는 요청이 매우 많은 부하를 만들었고 다음 두 번째 방법으로 전환해 갔다.
방법 2. Fan-out (팔로워들에게 트윗 전파)
팔로우들에게 캐시를 적용하는 방법이다. 사용자가 트윗을 하면 모든 팔로워들의 캐시 저장소를 탐색하여 각 캐시에 데이터를 insert 해준다. 각 사용자는 홈화면 캐시를 읽는다. 아마 각 Redis일 듯?
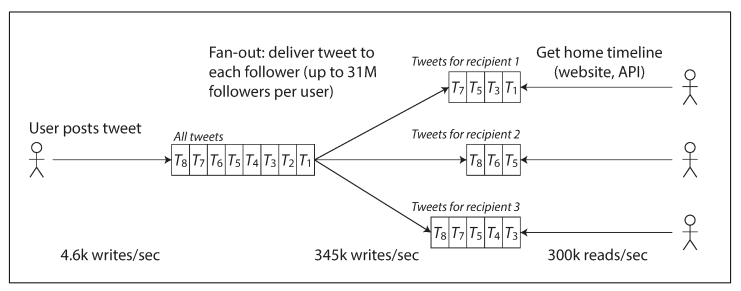
하지만 이 방법에도 단점이 있다. 팔로워가 많을수록 트윗에 따른 추가 작업이 매우 많아진다는 것이다. 만약 팔로워가 1억 명인 사용자가 트윗을 작성하면 1억 명의 팔로워들의 캐시를 탐색하며 캐시 데이터를 넣어주어야 한다. 즉 이 방법은 팔로워가 많을수록 트윗 작성자에게 부담을 준다.
따라서 트위터는 방법 1과 2를 모두 (hybrid) 적용했다. 셀럽과 같은 팔로워가 매우 많은 유저는 두 번째 방법 Fan-out에서 제외한다. 첫 번째 방법으로 셀럽들의 트윗을 홈 화면에 제공하고, 다른 일반 사용자들은 Fan-out을 사용해 트윗을 불러와 셀럽들의 데이터와 병합하여 제공된다. 대부분의 사용자는 Fan-out으로 트윗이 전파될 것이고, 팔로워가 매우 많은 (셀럽) 사용자들만 Global DB로부터 데이터를 읽도록 할 것이다. 아마 이 DB도 수천 개로 샤딩되어있을 것이다.
참고
https://product.kyobobook.co.kr/detail/S000001693775
데이터베이스 시스템 | Abraham Silberschatz - 교보문고
데이터베이스 시스템 |
product.kyobobook.co.kr
https://product.kyobobook.co.kr/detail/S000001766328
데이터 중심 애플리케이션 설계 | 마틴 클레프만 - 교보문고
데이터 중심 애플리케이션 설계 |
product.kyobobook.co.kr
https://product.kyobobook.co.kr/detail/S000201464167
카프카 핵심 가이드 | 그웬 샤피라 - 교보문고
카프카 핵심 가이드 |
product.kyobobook.co.kr
'Programming > Database System' 카테고리의 다른 글
| [Database] 데이터 타입 비교 : char vs varchar (0) | 2024.01.17 |
|---|---|
| [Database] Oracle Database Index (19c 기준) (1) | 2024.01.08 |
| [Database] 인덱스 (Index) 6장 : 쓰기에 최적화된 인덱스 (0) | 2023.11.08 |
| [Database] 인덱스 (Index) 5장 : Multiple-key Access (다중 키) (0) | 2023.10.20 |
| [Database] 인덱스 (Index) 4장 : Hash Index (0) | 2023.10.20 |




댓글