
목차
- 오라클의 인덱스
- 오라클에서 지원하는 데이터베이스 인덱스
- B-Tree 인덱스
- Bitmap 인덱스
- Funtion-Based 인덱스
- Application Domain 인덱스
- Index-Organized Tables
오라클의 인덱스
오라클 인덱스는 스키마 object로서 원천 데이터로부터 논리(물리)적으로 분리되어 있다. 그러므로 인덱스를 Drop 하면 여전히 데이터에는 액세스가 가능하다. (그러나 느리겠지)
인덱스는 빠르게 single row 로 찾아갈 수 있는 길이다. 오로지 실행 속도에 영향을 준다. 찾으려는 데이터 값이 인덱싱 되어있다면 인덱스를 통해 해당 값이 포함된 row로 곧장 갈 수 있다. 인덱스는 테이블의 1개 이상의 컬럼에 생성할 수 있다. 인덱스는 disk I/O를 줄여주는 여러 대안 중의 하나이다.
인덱스의 단점
- 인덱스를 생성하는 거는 데이터 모델, 어플리케이션, 분산 등에 깊은 이해가 필요하다
- 데이터나 모델링이 수정되면 기존의 인덱스를 재검토하여 인덱스의 효용가치를 다시 평가해봐야 한다
- 인덱스는 디스크 공간을 차지한다
- 인덱스 된 데이터에 DML이 발생하면 인덱스를 업데이트해야 한다 (overhead)
인덱스는 자동으로 데이터의 변화를 감지하여 갱신(유지)된다. retrieve 성능은 거의 상수에 가깝지만, 테이블에 인덱스가 너무 많으면 DML 성능을 저하시킬 수 있음을 유의해야 한다.
Oracle Database 19c는 Automated Indexing (자동생성 인덱스)가 있다. 데이터베이스가 지속적으로 application을 모니터링하여 인덱스를 자동으로 생성하고 관리하는 인덱스다. Automated Indexing는 고정 interval 마다 실행되는 task로 동작한다.
인덱스를 생성을 고민해 볼 만할 때
- 컬럼이 자주 쿼리되고, 리턴하는 %가 전체 row 수 대비 적을 때
- 참조 무결성 제약조건이 걸린 컬럼일 때
- Unique key 제약조건이 테이블에 생성되어 있고, 수동으로 인덱스를 특정하고 싶을 때
참조 무결성 제약조건이 생성된 컬럼에 대해서 부모 테이블의 primary key를 수정하거나 데이터를 merge, 삭제할 때 full table lock을 회피할 수 있다.
unusable index
인덱스는 기본적으로 usable이다. unusable index는 옵티마이저가 무시하고, DML 연산으로 유지되지 않는다. build load에 대한 성능 향상을 볼 수 있다.
invisible index
DML 연산에 의해 관리되지만 옵티마이저가 기본으로 사용하지 않는 인덱스다. unusable index나 인덱스를 삭제하는 것에 대한 대안이 될 수 있다. 특히 idex를 drop 하기 전에 테스트를 해보거나, 임시로 인덱스를 사용해보고 싶을 때 유용하다.
Composite Indexes (concatenated index, 복합 인덱스)
2개 이상의 컬럼에 대해 생성한 인덱스다. 질의할 컬럼 순서에 가장 근접한 순서로 복합 인덱스를 생성한다. (가장 중요) SELECT 문의 WHERE 절의 컬럼 순서와 가장 유사해야 한다. 일반적으로 가장 많이 사용되는 컬럼을 앞에 생성한다. 복합 인덱스에서 가장 앞에 오는 인덱스를 leading coulmn이라 한다.
- employees 테이블에 대한 SELECT 문의 WHERE 절 조건으로 last_name, job_id, salary 순으로 많이 사용하고,
- last_name의 카디널리티가 높을 때,
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);
-- 아래 모든 쿼리는 employees_ix를 사용한다.
SELECT *
FROM employees
WHERE last_name = 'Smith' AND job_id = 'SA_REP' AND salary = 5000;
SELECT *
FROM employees
WHERE last_name = 'Smith';
SELECT *
FROM employees
WHERE salary = 5000;
-- 아래 쿼리는 employees_ix를 사용하지 않는다.
SELECT *
FROM employees
WHERE job_id = 'SA_REP';몇 경우에서 leading column (복합 인덱스의 최우선 컬럼, 위의 last_name)의 카디널리티가 매우 낮다면, 데이터베이스는 Index Skip Scan을 한다.
Unique and Nonunique Indexes
오라클 데이터베이스는 row의 모든 key 컬럼이 null 인 경우 해당 row는 인덱싱 하지 않는다. (비트맵 인덱스, cluster key column 제외)
오라클에서 지원하는 데이터베이스 인덱스

B-Tree 인덱스
B-Tree는 오라클을 포함한 전 데이터베이스에서 가장 흔한 형태의 인덱스다. balanced tree (균형 트리) 형태로 구현된다.
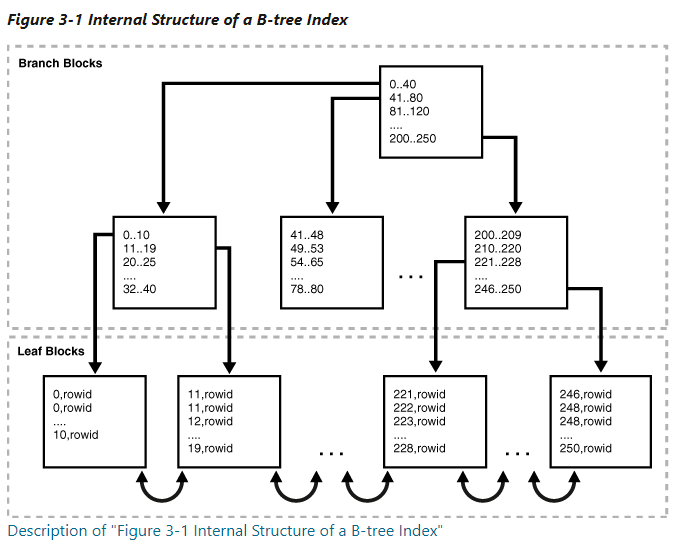
leaf node는 정렬된 리스트로 구현되며, 각 정렬된 리스트(노드)는 범위(range)를 가지고 있다. 각 노드는 key(인덱스 컬럼)와 row(or row 범위)로 구성된다. 주 용도는 range search, = 질의이다.
구조
B-Tree 인덱스는 크게 Branch block과 Leaf block으로 나뉜다. Branch block은 더 낮은 레벨의 block을 가리키는 인덱스 데이터로 구성된다. 위 그림에서 root node의 0... 40 인덱스 데이터는 가장 왼쪽의 level 1 노드를 가리킨다. 다시 해당 노드의 0.. 10 인덱스데이터는 가장 왼쪽 leaf node를 가리킨다.
leaf node에는 모든 인덱스 데이터에 해당하는 rowid (실제 row에 대한 포인터)를 가지고 있다. leaf node의 entry는 (key, rowid)로 정렬되어 있다. leaf node는 양쪽 형제 노드 (siblings) entry와 연결되어 있다. 즉 leaf node끼리는 이중 연결 리스트로 구현된다.
B-Tree 균형을 잡고 있어 모든 leaf block이 자동으로 동일한 깊이(depth)를 가진다. 그렇기 때문에 B-Tree 인덱스에 대한 모든 질의의 access time은 동일하다. (모든 leaf node에 대한 깊이가 같기 때문)
chracter 컬럼에 대한 인덱스는 글자의 binary 값을 기준으로 정렬되어 인덱스가 생성된다
Ascending and Descending Indexes
CREATE INDEX employees_ix
ON employees (last_name); -- 기본 : ASC
CREATE INDEX employees_ix
ON employees (last_name ASC, department_id DESC);
Index Scans : retrieve를 인덱스를 통해 수행하는 것
데이터베이스 질의가 인덱스를 통해 수행되는 것을 말한다. (보통 인덱스 태운다고 함) SELECT 문에 인덱스 컬럼을 특정해서 작성하여 Index Scans을 할 수 있다. Index Scans이 수행되면 n I/O (n = B-Tree 인덱스의 높이) 만큼을 수행하여 데이터를 찾는다.
SELECT 절에 인덱스 컬럼만 명시되어 있으면 인덱스만 탐색하여 완료할 수 있지만, 인덱스 컬럼 외의 컬럼도 질의에 포함하면 leaf node의 rowid를 사용해 실제 table row를 가져와야 한다.
Index Scans - Full Index Scan
인덱스 전체를 스캔하는 Index Scans이다.
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);
SELECT department_id, last_name, salary
FROM employees
WHERE salary > 5000
ORDER BY department_id, last_name;
오라클은 employees_ix를 전체 스캔해서 정렬된 순서대로 leaf node를 읽는다. 그 후 salary 가 5000을 넘는 인덱스 엔트리만 필터링한 다음 반환한다. 인덱스는 이미 정렬되어 있기 때문에 ORDER BY는 생략한다. 따라서 employees 테이블 전체를 스캔하지 않고 더 작은 데이터인 인덱스를 스캔해서 데이터를 반환할 수 있다.
Index Scans - Fast Full Index Scan
실제 테이블을 액세스 하지 않고 인덱스 스캔만으로 데이터를 반환하는 Index Scan을 말한다.
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);
SELECT last_name, salary
FROM employees;
Full table scan의 대안으로 사용될 수 있으며 다음과 같은 조건에서 Fast Full Index Scan이 가능하다.
- 쿼리에 필요한 모든 컬럼이 인덱스에 있을 때
- 쿼리 결과에 모든 컬럼이 null인 row가 없을 때 (인덱스 컬럼중 하나라도 NOT NULL 제약조건이 있거나, 쿼리에 NULL인 행을 필터링하도록 조건을 주었을 때
Index Scans - Index Range Scan
CREATE INDEX employees_ix
ON employees (last_name, salary);
SELECT last_name
FROM employees
WHERE last_name LIKE 'A%';
SELECT 조건에 하나 이상의 leading coulmn이 주어지고, 해당 조건에 부합하는 인덱스 key가 0개 이상인 경우에 수행되는 인덱스 스캔이다. 위 쿼리를 보면 last_name을 leading column으로 인덱스를 생성한 뒤, SELECT문의 WHERE 조건에 LIKE 'A%'를 주었다. 해당 조건에 부합하는 인덱스 key는 0개 이상이다.
leaf node의 앞 뒤로(형제끼리) 이동해 가면서 scan 하면서 Range Scan이 일어날 수 있다. 예를 들어 위 쿼리에서 last_name이 'A'로 시작하는 인덱스 엔트리가 2개 이상의 leaf node에 걸쳐 존재한다면, 제일 처음 leaf node를 찾고 오른쪽으로 형제 노드를 탐색해 나간다.
Index Scans - Index Unique Scan
UNIQUE 인덱스에 대해 = 조건을 주어 검색할 때 수행된다. 즉 인덱스 키가 최대 1개만 있는 검색을 수행할 때 진행된다.
CREATE UNIQUE INDEX employees_ix
ON employees (employee_id);
SELECT *
FROM employees
WHERE employee_id = 5;
Index Scans - Index Skip Scan
CREATE INDEX employees_ix
ON employees (gender, job_id);
SELECT *
FROM employees
WHERE job_id = 'JOB_SALARY';SELECT *
FROM employees
WHERE gender = 'F' AND job_id = 'JOB_SALARY'
UNION ALL
SELECT *
FROM employees
WHERE gender = 'M' AND job_id = 'JOB_SALARY';Index Clustering Factor : 인덱스 순서와 row의 data block 순서가 얼마나 비슷한가
- factor가 높을수록, 오라클은 Index Range Scan을 크게 할수록 높은 I/O를 수행해야한다. 인덱스 엔트리는 random table block을 가리키기 때문이다.
- factor가 낮을수록, 오라클은 Index Range Scan을 크게할 수록 적은 I/O를 수행할 수 있다. 인덱스 엔트리가 가리키는 data block이 동일할 확률이 높기 때문이다.
SQL> CREATE INDEX EMP_NAME_IX ON EMP (last_name);
SQL> CREATE INDEX EMP_EMP_ID_PK ON EMP (employee_id);
SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
2 FROM ALL_INDEXES
3 WHERE INDEX_NAME IN ('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2
테이블의 last_name과 employee_id에 각각 인덱스가 생성되어 있고, 실제 data block에 저장된 순서는 last_name으로 정렬되어 있다면, 위처럼 clustering factor는 employee_id에 대한 인덱스가 더 높게 나온다. (=인덱스 스캔 시 더 많은 block I/O가 발생)
Reverse Key Indexes
Oracle RAC 데이터베이스에서 유용하다. 여러 인스턴스가 같은 block에 인덱스 엔트리를 추가하기 위해 경합하는 것을 방지한다.
인덱스 leaf block이 인덱스 키를 기준으로 정렬되어있지 않기 때문에, Index Range Scan을 어렵게 한다는 것을 주의하자.
Index Compression (인덱스 압축)
CREATE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );위처럼 인덱스를 만들고, 실제 인덱스 엔트리가 아래와 같다면,
online,0,AAAPvCAAFAAAAFaAAa
online,0,AAAPvCAAFAAAAFaAAg
online,0,AAAPvCAAFAAAAFaAAl
online,2,AAAPvCAAFAAAAFaAAm
online,3,AAAPvCAAFAAAAFaAAq
online,3,AAAPvCAAFAAAAFaAAt오라클은 Prefix Compression (key compression)을 수행해 아래처럼 prefix를 공유하여 인덱스 엔트리를 형성한다.
online,0
AAAPvCAAFAAAAFaAAa
AAAPvCAAFAAAAFaAAg
AAAPvCAAFAAAAFaAAl
online,2
AAAPvCAAFAAAAFaAAm
online,3
AAAPvCAAFAAAAFaAAq
AAAPvCAAFAAAAFaAAt
COMPRESS 키워드로 인덱스 생성 시 압축을 명령할 수 있지만, 위 생성문에서 오라클은 중복 key (order_mode, order_status)를 감지하여 prefix로 잡고 압축한다.
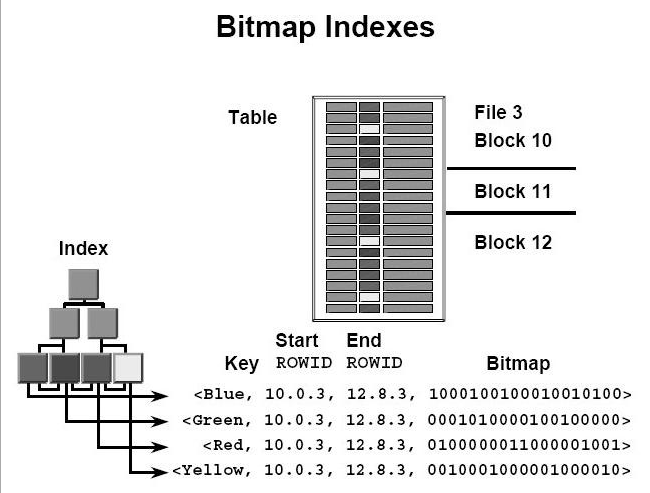
Bitmap 인덱스
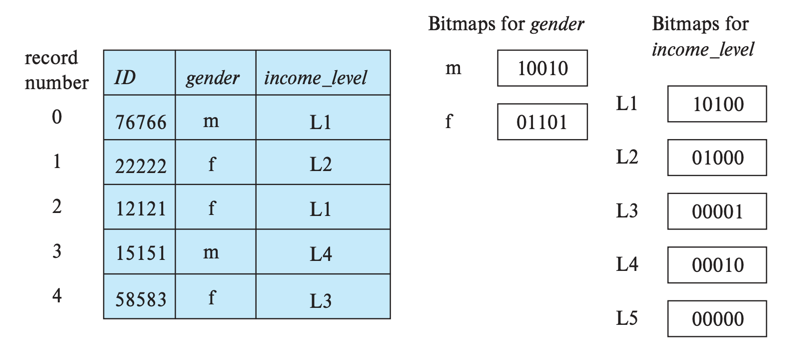
인덱스 key마다 비트맵을 저장한다. B-Tree 인덱스는 하나의 인덱스 key가 하나의 row를 가리킨다면 (밀집 인덱스), Bitmap 인덱스는 하나의 인덱스 key가 여러 row를 가리킬 수 있다. 다음의 경우 비트맵 인덱스를 고려해 볼 만하다.
- 인덱스 컬럼의 카디널리티가 낮을 때 (성별, 상태 등)
- 테이블이 read-only이거나 DML 문으로 큰 수정이 일어나지 않을 때
- 데이터 웨어하우징 (DW)
- 쿼리에서 즉석으로 여러 컬럼을 참조할 때
아주 대표적으로 성별 컬럼이 있다. 성별 컬럼은 크게 (남, 여) 두가지 값만 가지므로 카디널리티가 상당히 낮은 컬럼이다.
특정 row의 인덱스 컬럼의 값이 수정되면, 오라클은 인덱스 key 엔트리에 lock을 잡는다. (실제 row에 매핑되어 있는 bit가 아닌) 인덱스 key는 여러 row를 가리키고 있기 때문에 값이 수정되면 해당 여러 row를 가리키는 인덱스 entry에 lock을 잡기 때문에 비트맵 인덱스는 OLTP 애플리케이션에 적합하지 않다.
SQL> CREATE BITMAP INDEX employees_bix ON employees (gender);
SQL> CREATE BITMAP INDEX employees_bix ON employees (status);
SQL> SELECT cust_id, cust_last_name, status, gender
2 FROM employees
3 WHERE ROWNUM < 8 ORDER BY cust_id;
CUST_ID CUST_LAST_NAME STATUS GENDER
---------- ---------- -------- -
1 Kessel M
2 Koch F
3 Emmerson divorced M
4 Hardy M
5 Gowen M
6 Charles single F
SQL> SELECT COUNT(*)
2 FROM employees
3 WHERE gender = 'F' AND status IN ('single', 'divorced');
COUNT(*)
----------
1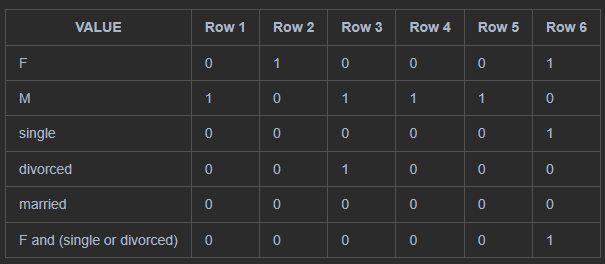
Bitmap Join Indexes
2개 이상의 테이블을 join 할 때 전용으로 사용할 비트맵 인덱스를 말한다.
-- employees 테이블에 jobs.job_title 컬럼에 대한 비트맵 인덱스 생성
CREATE BITMAP INDEX employee_bm_idx
ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;
SELECT COUNT(*)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
AND jobs.job_title = 'Programmer';
SELECT jobs.job_title AS "jobs.job_title", employees.rowid AS "employees.rowid"
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
ORDER BY job_title;
먼저 employees 테이블에 jobs.job_title을 인덱스 키로 비트맵 인덱스를 생성한다. 이 인덱스 key (job_title)은 employees 테이블 row를 가리킨다. 가리키는 조건은 (employees.job_id = jobs.job_id)이다.
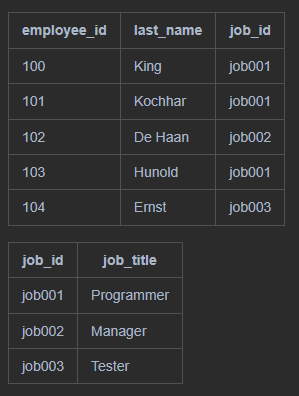
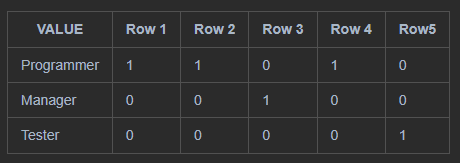
비트맵 인덱스 구조
오라클은 비트맵 인덱스 key를 B-Tre 인덱스로 저장한다. 예를 들어, employee에 gender 컬럼에 비트맵 인덱스가 생성되면, 인덱스 key를 gender로 하는 B-Tree 인덱스를 생성한다. leaf block은 각 인덱스 key에 대한 row 별 비트맵을 저장한다.
Funtion-Based 인덱스
오라클 Funtion-Based 인덱스는 하나 이상의 컬럼에 대해서 함수 (혹은 표현식)를 적용한 값을 인덱스에 저장한다. 비트맵 인덱스이거나 B-Tree 인덱스일 수 있다. funtion은 산술식, SQL 함수, PL/SQL funtion, C 가 가능하다.
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);
SELECT employee_id, last_name, first_name,
12 * salary * commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000
ORDER BY "ANNUAL SAL" DESC;
CREATE INDEX emp_fname_uppercase_idx
ON employees ( UPPER(first_name) );
CREATE INDEX cust_valid_idx
ON customers ( CASE cust_valid WHEN 'A' THEN 'A' END );
WHERE 절에 함수가 포함된 조건이 있고, 동일한 조건으로 Funtion-Based 인덱스가 생성되어있다면 Funtion-Based 인덱스로 Index Range Scan이 가능하다. 예를 들어, 12 * salary * commission_pct으로 Function-Based 인덱스가 생성되어 있고, WHERE 절에 동일한 조건이 있다면 인덱스를 사용한다.
오라클은 대소문자와 공백 구분 없이 Fuction-Based 인덱스를 사용한다.
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);
SELECT employee_id, last_name, first_name,
12 * salary * commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000;
SELECT employee_id, last_name, first_name,
12 * salary * commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12*salary*commission_pct) < 30000;
SELECT employee_id, last_name, first_name,
12 * salary * commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * SALARY * COMISSION_PCT) < 30000;Application Domain 인덱스
애플리케이션에 특화되도록 커스터마이징 된 인덱스다. 특수한 데이터 타입 (문서, 공간, 이미지, 비디오 클립과 같은 비정형 데이터)을 수용할 수 있고, 특화된 인덱싱 기술을 적용한다. 인덱스 자체는 index-organized table이나 외부 파일로 저장될 수 있다. cartridge라는 애플리케이션 소프트웨어로 도메인 인덱스를 관리한다. 더 궁금한 분은 아래 오라클 가이드를 참고 바란다.
https://docs.oracle.com/pls/topic/lookup?ctx=en/database/oracle/oracle-database/19/cncpt&id=ADDCI110
Index-Organized Tables
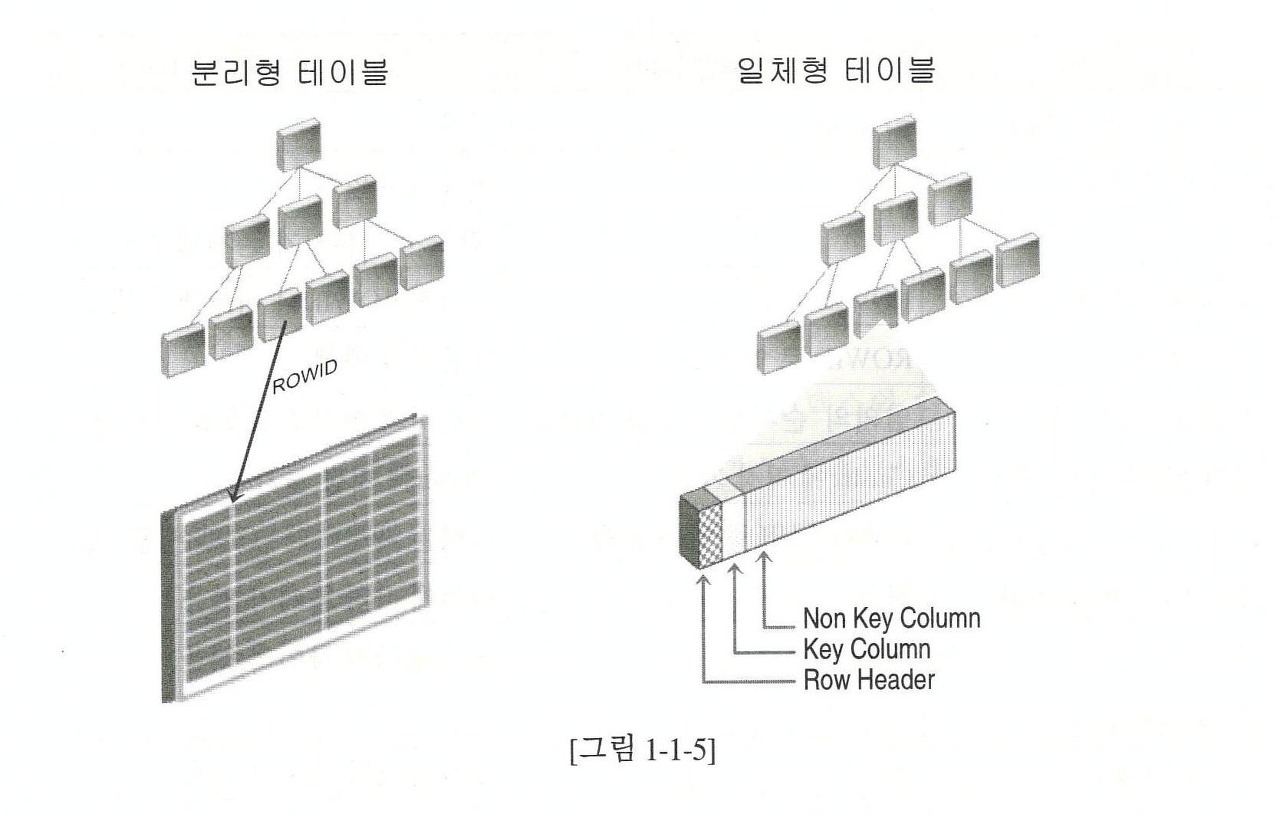
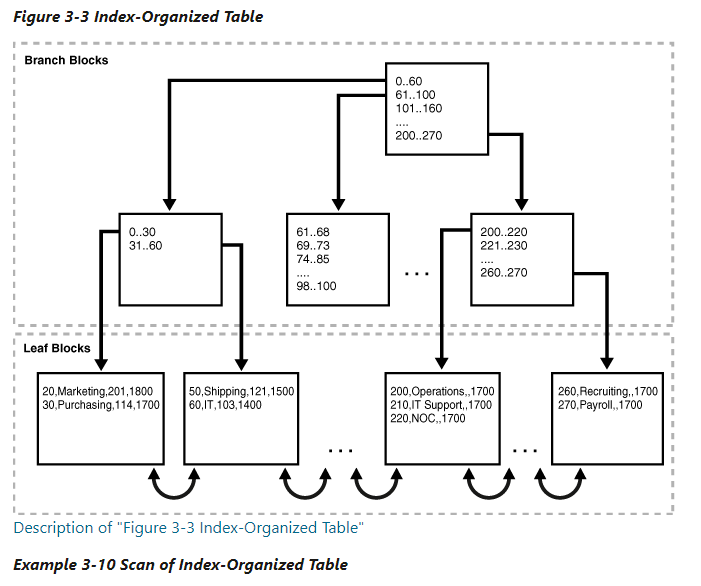
B-Tree 인덱스를 변형하여 테이블을 저장한다. Index-Organized Table에서 row는 table의 primary key에 생성한 인덱스에 저장된다. 위 그림처럼 인덱스 key가 아닌 컬럼 또한 모두 leaf node에 저장된다. 그러므로 인덱스가 곧 데이터 (row)고, 데이터가 곧 인덱스다. leaf block에 rowid를 저장하지 않는다. 대신 primary key를 저장한다.
Index-Organized Table은 table row에 더 빠르게 액세스 하게 한다. 당연히 non-key 컬럼도 leaf node에 있으니 인덱스 접근 외의 추가적인 block I/O 는 필요 없다. 인덱스 컬럼 외의 데이터가 반드시 인덱스에 저장되어야 하거나, 인덱스 순서와 row 저장 순서가 동일해야하는 경우 유용하다. (OLAP 애플리케이션)
Row Overflow Area
Index-Organized Table을 생성할 때 별도의 세그먼트에 Row Overflow Area를 생성할 수 있다. Index-Organized Table는 전체 row를 Leaf Block에 저장하기 때문에 인덱스 자체가 매우 커질 수 있다. 따라서 Row Overflow Area를 지정하면 오라클은 아래와 같이 Index-Organized Table을 분리하여 저장한다.
- 인덱스 엔트리 (인덱스 세그먼트) : 여기에는 primary key 컬럼 값, overflow를 가리키는 rowid, optional하게 non-key 컬럼을 저장
- overflow (overflow storage area 세그먼트): non-key 컬럼
- 값 저장
보조 인덱스 (Secondary Indexes)
오라클은 Index-Organized Table에 접근할 때 logical rowid (row 식별자)를 사용한다. logical rowid는 테이블 primary key를 base64로 인코딩한 값이다. Index-Organized Table의 leaf node에는 row의 영구적인 물리 주소값이 없기 때문에 오라클은 primary key 기반의 logical rowid를 사용한다.
즉, Index-Organized Table의 row는 모두 leaf node에 저장되고, leaf node는 인덱스 구조가 변함에 따라 이동해 다닐 수 있으므로, 각 인덱스 엔트리를 식별할 수 있도록 logical rowid를 사용한다.
Index-Organized Table에 대한 인덱스를 말한다. 즉 인덱스에 대한 인덱스다. 예를 들어 departments 테이블이 Index-Organized Table이고, location_id에 대해 보조 인댁스를 생성한다면, 이 Index-Organized Table에 대한 보조인덱스의 인덱스 엔트리는 아래와 같다.
<location_id, departments 의 logical id>
1700,*BAFAJqoCwR/+
1700,*BAFAJqoCwQv+
1800,*BAFAJqoCwRX+
2400,*BAFAJqoCwSn+
Physical Guesses
logical rowid에는 실제 해당 인덱스 엔트리가 생성될 당시의 물리적 주소값을 가지는 Physical Guesses가 포함되어 있다. Physical Guesses는 실제 인덱스 엔트리가 물리적으로 이동하더라도, 갱신되지 않은 채 logical rowid에 포함되어 있다. Physical Guesses가 정확한 경우 보조 인덱스를 scan 한 다음 해당 row의 block을 읽기 위한 I/O만 추가로 필요하다. Physical Guesses가 부정확하면, 보조 인덱스 scan + row block을 읽기 위한 I/O (실패) + Index Unique Scan 이 필요하다.
참고
Database Concepts
Indexes are schema objects that can speed access to table rows. Index-organized tables are tables stored in an index structure.
docs.oracle.com
http://www.gurubee.net/lecture/2959
리버스 키 인덱스의 개념
리버스 키(Reverse Key) 인덱스는 B*TREE 인덱스와 거의 같다. 단지 인덱스 키 값을 반대로 구성해 비트리 인덱스를 생성할 뿐이다. 그로 인한 몇..
www.gurubee.net
http://www.gurubee.net/wiki/pages/26742998
비트맵 인덱스.
www.gurubee.net
http://www.gurubee.net/lecture/2601
인덱스 일체형 테이블(Index-Organized Table)
1.2. 인덱스 일체형 테이블(Index-Organized Table)1.2.1 분리형과 일체형의 비교1.2.2 일체형 테이블의 구조 및 특징1.2.3 논리적ROWID와 물리적 주..
www.gurubee.net
'Programming > Database System' 카테고리의 다른 글
| [Database] 빅 데이터 (Big Data) 1장 - Big Data Storage System (0) | 2024.04.13 |
|---|---|
| [Database] 데이터 타입 비교 : char vs varchar (0) | 2024.01.17 |
| [Message Brokers] Streaming data와 Pub / Sub system (1) | 2023.11.25 |
| [Database] 인덱스 (Index) 6장 : 쓰기에 최적화된 인덱스 (0) | 2023.11.08 |
| [Database] 인덱스 (Index) 5장 : Multiple-key Access (다중 키) (0) | 2023.10.20 |




댓글