
목차
- 인덱스를 이용한 정렬 (extra에 별도 표기 없음)
- driving table만 정렬 (Using filesort)
- 임시 테이블을 이용한 정렬 (Using temporary; Using filesort)
MySQL에서 ORDER BY (정렬)을 처리하는 방식은 크게 2가지가 있다. 인덱스를 활용하는 인덱스 정렬과, 메모리 (혹은 디스크까지)를 활용해서 정렬하는 filesort이다. 이 2가지 방법을 토대로 옵티마이저는 크게 세 가지 형태로 정렬을 진행할 수 있는데 결론부터 말하자면,
- 가능하다면 인덱스를 사용한 정렬로 유도 하고, (인덱스 정렬)
- 그렇지 못하면 최소한 드라이빙 테이블만 정렬해도 되는 수준으로 유도하는 것이 좋은 튜닝방법이다. (filesort)
- 그렇지 않으면 임시 테이블을 이용해 정렬하게 되는데 이는 가장 느린 방법이다. (filesort)

예제로 준비한 2개의 테이블이 있다. team (팀)과 player (선수) 테이블이고, team에는 1,000건, player에는 100,000건의 레코드가 있다.
DDL
SET GLOBAL log_bin_trust_function_creators = 1;
-- create country table
DROP TABLE IF EXISTS team;
CREATE TABLE team
(
id INT,
PRIMARY KEY (id),
name VARCHAR(50) NOT NULL
) ENGINE = InnoDB;
CREATE INDEX idx_team_1 ON team (name);
DROP FUNCTION IF EXISTS make_team;
DELIMITER //
CREATE FUNCTION make_team()
RETURNS INT
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000
DO
INSERT INTO team (id, name)
VALUES (i, CONCAT('team ', FLOOR(RAND() * 100) + 1));
SET i = i + 1;
END WHILE;
RETURN i;
END //
DELIMITER ;
SELECT make_team();
DROP TABLE IF EXISTS player;
CREATE TABLE player
(
id INT,
PRIMARY KEY (id),
id_team INT NOT NULL,
name VARCHAR(200) NOT NULL,
avg_rate INT DEFAULT 0,
position VARCHAR(20)
) ENGINE = InnoDB;
CREATE INDEX idx_player_1 ON player (id_team);
CREATE INDEX idx_player_2 ON player (position, avg_rate);
DROP FUNCTION IF EXISTS make_player;
DELIMITER //
CREATE FUNCTION make_player()
RETURNS INT
BEGIN
DECLARE cnt INT DEFAULT 100000;
DECLARE i INT DEFAULT 1;
WHILE i <= cnt
DO
INSERT INTO player (id, id_team, name, avg_rate, position)
VALUES (i, FLOOR(RAND() * 1000) + 1, CONCAT('player ', FLOOR(RAND() * cnt)), FLOOR(RAND() * 100),
ELT(1 + FLOOR(RAND() * 4), 'F', 'M', 'D', 'G'));
SET i = i + 1;
END WHILE;
RETURN i;
END //
DELIMITER ;
SELECT make_player();
1. 인덱스를 이용한 정렬 (extra에 별도 표기 없음)
인덱스 순서대로 읽기만 하면 되는 정렬 방법이다. 다음 조건이 모두 만족해야 가능하다.
- 조건 1. ORDER BY의 컬럼이 제일 먼저 읽는 테이블 (조인 시 driving table)에 속함
- 조건 2. ORDER BY의 컬럼 명시 순서와 동일한 인덱스
- 조건 3. WHERE 절의 조건 중 driving table의 인덱스 조건과 동일한 조건이 있음 (위에서 name 컬럼)
SELECT t.id, t.name, p.id, p.name
FROM team t
inner join player p on t.id = p.id_team
WHERE t.name like 'team 1%'
ORDER BY t.name ASC;
인덱스 조건에 부합해도 인덱스를 사용하여 정렬하지 않을 때도 있다. 옵티마이저는 인덱스를 사용하여 정렬하는 방법이 table scan보다 더 빠르다고 판단할 때에만 인덱스 정렬을 사용한다.
SELECT * -- 컬럼 수 총 17개
FROM player_extra_cols
ORDER BY id_team asc;-- (id_team)으로 인덱스가 있는 상태
위 쿼리는 인덱스를 사용하여 정렬하더라도 SELECT * 때문에 인덱스에 있지 않은 컬럼들도 모두 불러와야 한다. (위 테이블의 컬럼은 16개) 옵티마이저는 인덱스를 사용하여 정렬(+ SELECT 한 컬럼을 불러오는 작업)하는 것보다 전체 table scan을 한 뒤 정렬하는 것이 더 빠르다고 판단하여 전체 table scan 한다. 따라서 다음에 소개할 filesort를 한 것이다.
2. driving table만 정렬 (Using filesort)
지금부터는 인덱스를 사용하지 않고 데이터베이스의 메모리 (혹은 부족하다면 디스크)를 사용해 정렬하는 방법이다. 인덱스를 사용하여 정렬이 불가능한 상황이나 table scan이 더 효율적일 경우 MySQL은 filesort를 수행하는데 filesort란 메모리를 사용해 table scan 하여 정렬하는 방식이다. 시스템 변수 sort_buffer_size 만큼의 메모리를 할당받아 정렬을 수행한다. 정렬 수행하기에 할당받은 메모리가 부족하다면 임시 디스크 파일을 생성하여 정렬한다.
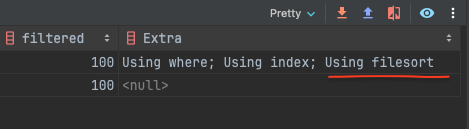
조인 시 결과 레코드 수와 레코드 하나당 크기가 몇 배씩 늘어나기 때문에 조인이 일어나기 전에 먼저 정렬할 수 있으면 좋다. 이게 가능하기 위해서는 driving table (조인 시 가장 먼저 읽는 테이블)의 컬럼 만으로 정렬이 가능해야 한다. 즉 driving table의 컬럼만으로 order by를 작성했다면, driving table 먼저 정렬 후 조인이 일어날 수 있어 효율적이다.
SELECT t.id, t.name, p.id, p.name
FROM team t
INNER JOIN player p ON t.id = p.id_team
WHERE t.name like 'team 1%'
ORDER BY t.id ASC;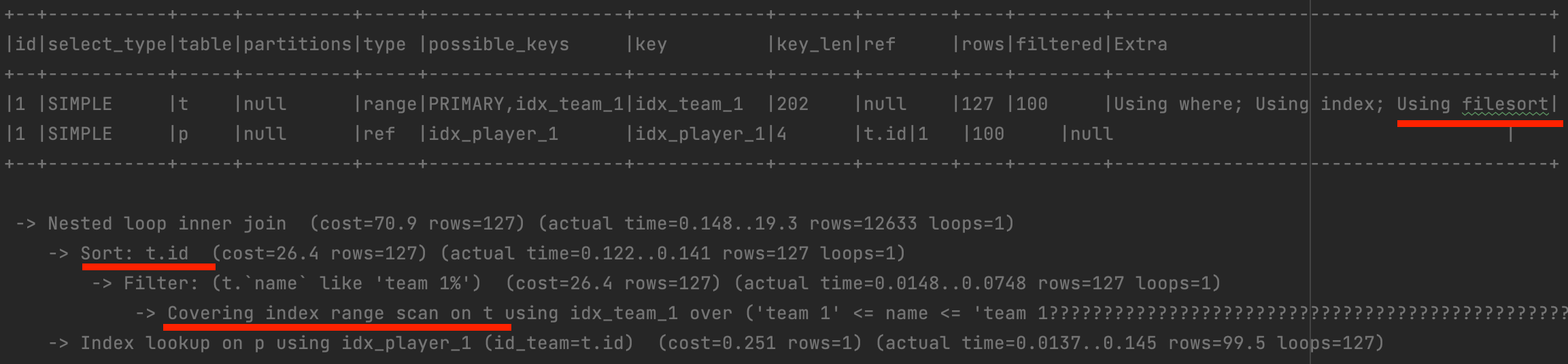
3. 임시 테이블을 이용한 정렬 (Using temporary; Using filesort)
그 외의 경우 정렬을 위해 임시 테이블을 만들어 조인 결과를 저장한 다음 정렬 작업을 추가적으로 해야한다. 가장 느린 정렬 방법이다.
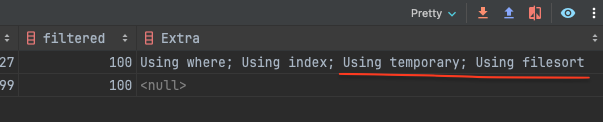
SELECT t.id, t.name, p.id, p.name
FROM team t
INNER JOIN player p ON t.id = p.id_team
WHERE t.name like 'team 1%'
ORDER BY p.id ASC;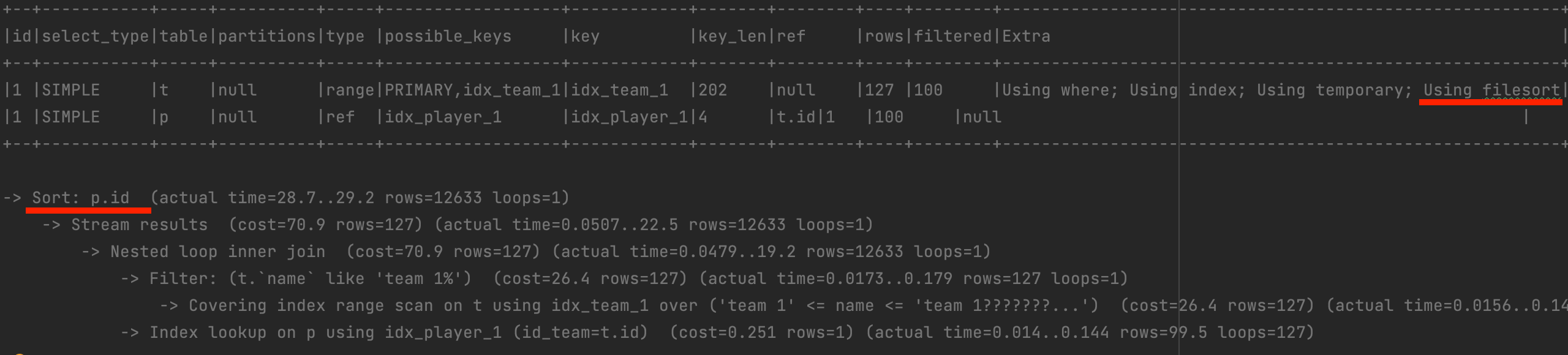
참고
https://dev.mysql.com/doc/refman/8.4/en/order-by-optimization.html
MySQL :: MySQL 8.4 Reference Manual :: 10.2.1.16 ORDER BY Optimization
10.2.1.16 ORDER BY Optimization This section describes when MySQL can use an index to satisfy an ORDER BY clause, the filesort operation used when an index cannot be used, and execution plan information available from the optimizer about ORDER BY. An ORDE
dev.mysql.com
https://product.kyobobook.co.kr/detail/S000001766482
Real MySQL 8.0 (1권) | 백은빈 - 교보문고
Real MySQL 8.0 (1권) | MySQL 서버를 활용하는 프로젝트에 꼭 필요한 경험과 지식을 담았습니다!《Real MySQL 8.0》은 《Real MySQL》을 정제해서 꼭 필요한 내용으로 압축하고, MySQL 8.0의 GTID와 InnoDB 클러스
product.kyobobook.co.kr
'Programming > Database System' 카테고리의 다른 글
| MySQL 타임존 다루기 (0) | 2025.01.20 |
|---|---|
| [Database] 빅 데이터 (Big Data) 1장 - Big Data Storage System (0) | 2024.04.13 |
| [Database] 데이터 타입 비교 : char vs varchar (0) | 2024.01.17 |
| [Database] Oracle Database Index (19c 기준) (1) | 2024.01.08 |
| [Message Brokers] Streaming data와 Pub / Sub system (1) | 2023.11.25 |




댓글